RLAIF-V
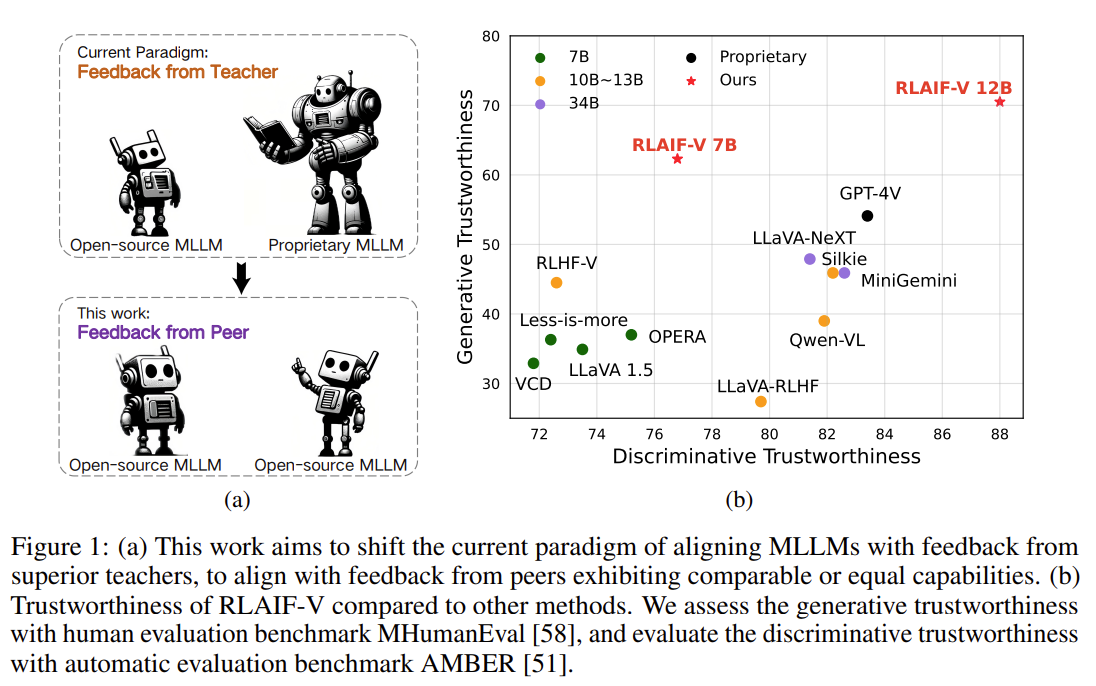
In order to align MLLMs with human preferences, reinforcement learning from human feedback (RLHF) has been widely used and demonstrates substantial results [49, 58]. However, RLHF depends heavily on labor-intensive human annotations, and consequently is hard to cover the widespread misalignment between model and human preferences. Recently, reinforcement learning from AI feedback (RLAIF), which uses the preference collected from labeler models as a proxy of human preference, has shown promising potential as an alternative to RLHF [22].
existing RLAIF drawbacks:
- expensive api
- gap shirnk
To address the challenges, we propose the RLAIF-V framework, which aligns MLLMs using opensource feedback, achieving more trustworthy behavior compared with the labeler and even GPT4V
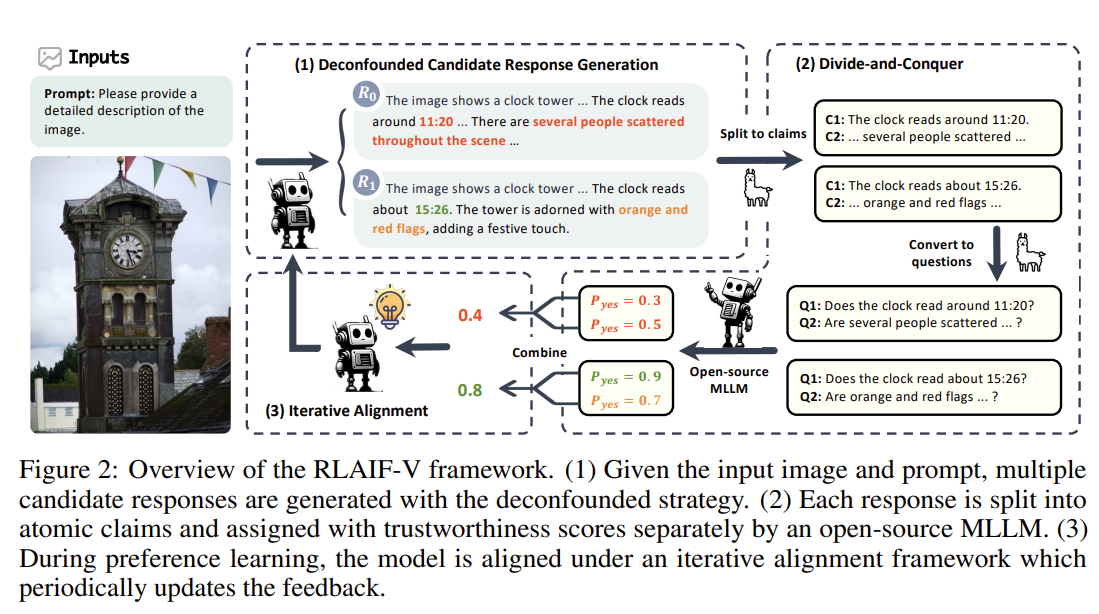
Response Generation
The feedback collected for preference learning is in the form of comparison pairs: \((y_w, y_l, x)\) , which represents win, lose, prompt and image repectively.
During training, the model learns preferences by distinguishing the differences between \(y_w\) and \(y_l\). To expose the genuine differences in trustworthiness between responses, we propose a novel deconfounded strategy to generate candidate responses \(\left\{y_1, y_2, \cdots, y_n\right\}\) through sampling decoding with different random seeds, where input \(x\) and decoding parameters are invariant. In this way, \(y_w\) and \(y_l\) are sampled from the same distribution and consequently share similar textual styles and linguistic patterns. During training, the model can effectively concentrate on the differences in trustworthiness.
Response Evaluation
We employ a divide-and-conquer approach to simplify the task to achieve more reliable results from open-source MLLMs.
Divide.
Reduce the complexity of full responses. Decompose the response evaluation into atomic claim evaluation. We prompt a large language model to split a response \(y\) into atomic claims \(\left\{c_1, c_2, \cdots, c_m\right\}\), which can be evaluated separately, by extracting facts excluding opinions and subjective statements. (Llama)
Conquer.
- we first convert it into a polar question like “Does the clock read around 11:20?”, which can be answered with simply yes or no
- For each atomic polar question, we ask an open-source MLLM to generate the confidence of agreement and disagreement as the claim score \(s_c=\left(p_{y e s}, p_{n o}\right)\), where \(p_{y e s}\) is the probability of answering with "Yes" or "yes" and \(p_{n o}\) is the probability of answering with "No" or "no". A higher \(p_{y e s}\) score suggests the corresponding claim is considered more trustworthy by the labeler model.
Combine.
\(score = -n_{rej} = -\sum_c p_{no} > p_{yes}\)
To save the training cost, for each instruction \(x\), we randomly sample at most 2 pairs \((y, y')\) as \((y_w, y_l)\) where \(s > s'\)
Iterative Alignment
DPO is widely used to align MLLMs with human preference. However, naive DPO faces the distribution shift problem, i.e., the preference data is static during training process while model output distribution is constantly shifting. As a result, the data distribution might deviate from the expected feedback distribution and cause sub-optimal alignment results. We tackle this problem by conducting the alignment process including both data collection and training in an iterative manner.
