Taming Transformers
Taming Transformers for High-Resolution Image Synthesis
Introduction
We demonstrate how combining the effectiveness of the inductive bias of CNNs with the expressivity of transformers enables them to model and thereby synthesize high-resolution images.
CNN vs Transformers
- CNNS: inductive prior, designed to exploit prior knowledge about strong local correlations within images
- Transformers: no built-in inductive prior, free to learn complex relationships among its inputs.
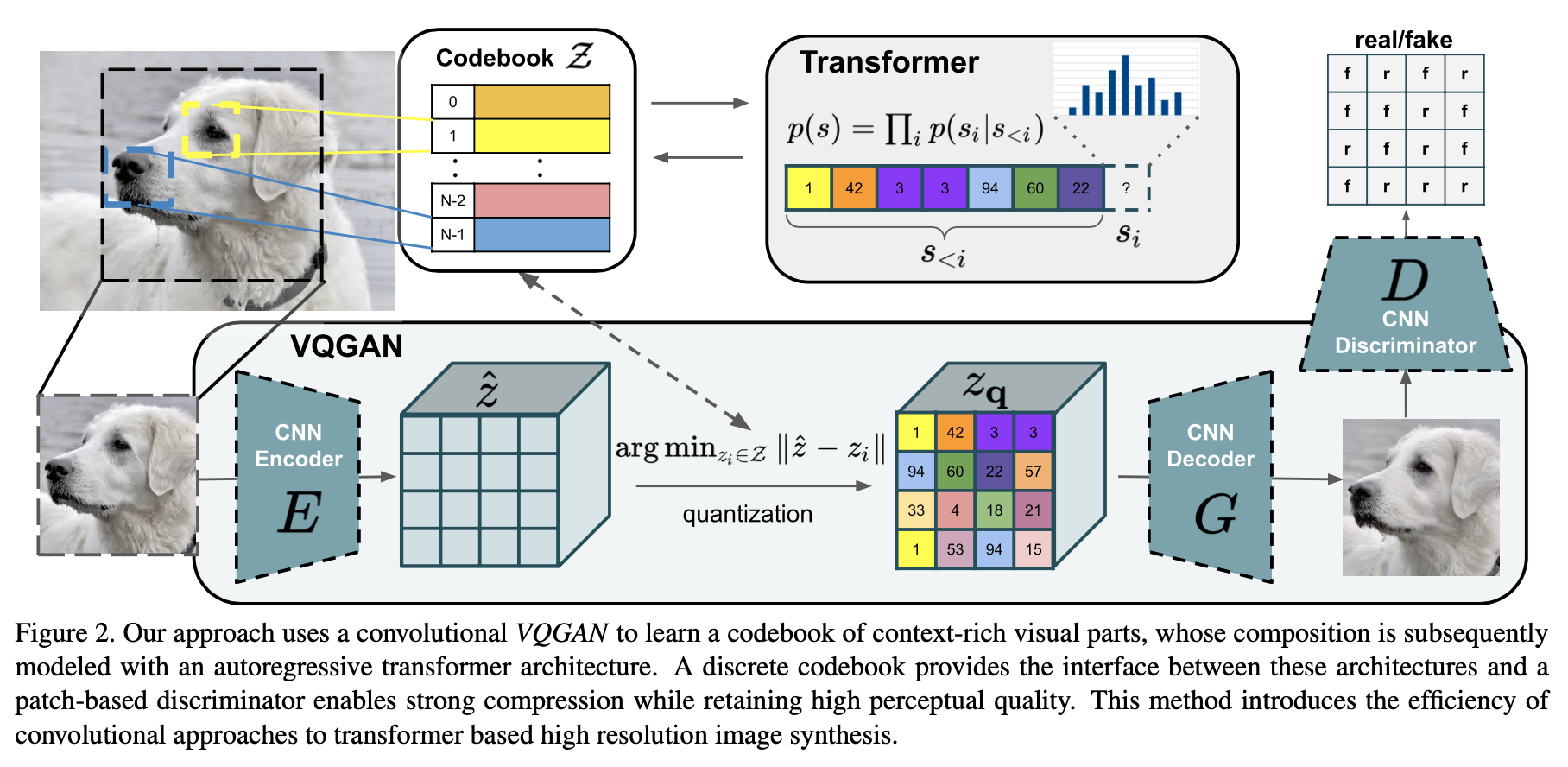
How to obtain an effective and expressive model?
Problem: low-level image structure is well described by CNN while it ceases to be effective on higher semantic levels.
Method:
use a convolutional approach to efficiently learn a codebook of context-rich visual parts
use transformer to learn the long-range interactions within these compositions
use an adversarial approach to ensure that the dictionary of local parts captures perceptually important local structure