SuPIR
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up
Abstract
We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations. we introduce negative-quality prompts to further improve perceptual quality. We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration.
Introduction
Development of Image Restoration (IR)
- IR methods based on generative priors: [42] (Denoising diffusion restoration models), [49] [diffbir], [65] (High-resolution image synthesis with latent diffusion models), [79] (Zero-shot image restoration using denoising diffusion null-space model) with model scaling being a crucial and effective approach
In this work, we introduce SUPIR (Scaling-UP IR), the largest-ever IR method
- Model: SDXL
- Adaptor: ZeroSFT connector
- Dataset: 20 million high-quality, high-resolution images, each accompanied by detailed descriptive text. We utilize a 13-billion-parameter multi-modal language model to provide image content prompts, greatly improving the accuracy and intelligence of our method.
Our work goes far beyond simply scaling.
Challenges: Existing adaptor designs either too simple to meet the complex requirements of IR [57] or are too large to train together with SDXL:
Solution: Introduce ZeroSFT connector.
- we fine-tune the image encoder to improve its robustness to variations in image degradation.
- we collect 20 million high-quality, high-resolution images with descriptive text annotations. We employ a counter-intuitive approach by integrating poor-quality samples into our training process. This allows us to enhance visual effects by utilizing prompts to guide the model away from negative qualities.
- Finally, powerful generative prior is a double-edged sword. To address the issue of low fidelity, we introduce the concept of restoration-guided sampling. By integrating these strategies with efficient engineering practices, we not only facilitate the scaling up of SUPIR but also push the frontiers of advanced IR.
Related Work
Image Restortion
The goal of IR is to convert degraded images into high-quality degradation-free images.
In the early stage: these methods are often based on specific degradation assumptions [25, 50, 56] and therefore lack generalization ability to other degradations [29, 52, 94].
SR: [Dual aggregation transformer for image super-resolution], [Image super-resolution using deep convolutional net-
works], [Accelerating the super-resolution convolutional neural network.]
Denoising: [Masked image training for generalizable deep image denoising], [Residual learning of deep cnn for image denoising], [Ffdnet: Toward a fast and flexible solution for cnn-based image denoising]
Deblurring: [Hierarchical integration diffusion model for realistic image deblurring], [Deep multi-scale convolutional neural network for dynamic scene deblurring], [Scale-recurrent network for deep image deblurring]
DiffBIR [49] unifies different restoration problems into a single model. In this paper, we adopt a similar setting to DiffBIR and use a single model to achieve effective processing of various severe degradations.
Generative Prior
- GANs
- Diffusion models: Diffusion models have also been effectively used as generative priors in IR
Model Scaling
use LLM and MLLM like Llava as examples
Method
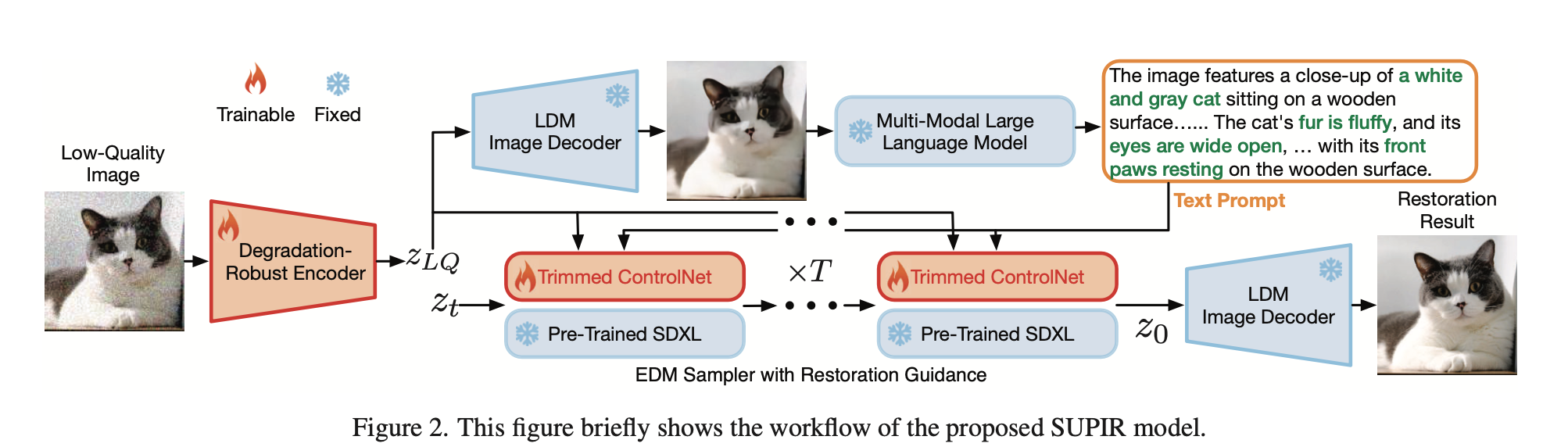
Network design
- Base Model: SDXL. Additionally, SDXL employs a Base-Refine strategy. the dual-phase design of SDXL becomes redundant for our objectives. We opt for the Base model, which has a greater number of parameters, making it an ideal generative prior.
- Degradation-Robust Encoder:
- Reason: original encoder has not been trained on LQ images
- Solution: fine-tune the encoder, fix the decoder.
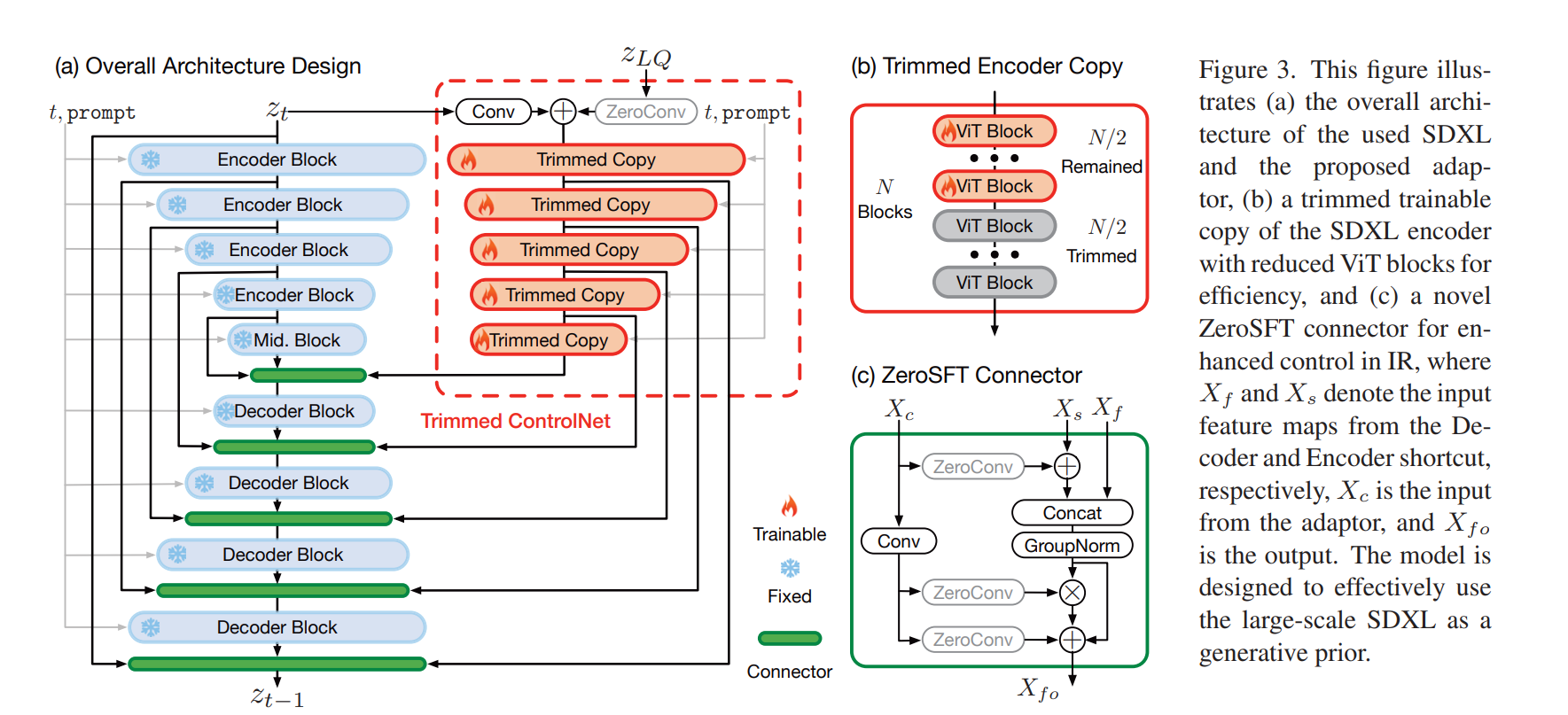
- Adaptor Design
- First, we keep the high-level design of ControlNet but employ network trimming [33] to directly trim some blocks within the trainable copy, achieving an engineering-feasible implementation. We simply trim half of the ViT blocks from each encoder block, as shown in Fig. 3(b).
- Second, we redesign the connector that links the adaptor to SDXL. To amplify the influence of LQ guidance, we introduced a ZeroSFT module, as depicted in Fig. 3(c). Building based on zero convolution, ZeroSFT encompasses an additional spatial feature transfer (SFT) [76] operation and group normalization [81].
Training Data
Image Collection
- Problem: There is no large-scale high-quality image dataset available for IR yet. Larger datasets like ImageNet (IN) [17], LAION-5B [67], and SA-1B [44] contain more images, but their image quality does not meet our high standards.
- Solution: To this end, we collect a large-scale dataset of high-resolution images, which includes 20 million 1024×1024 high-quality, texture-rich images. We also included an additional 70K unaligned high-resolution facial images from the FFHQ-raw dataset [40] to improve the model’s face restoration performance.
Multi-Modality Language Guidance
Hypothesis: We believe that textual prompts can also aid IR. Textual prompts can serve as a control mechanism, enabling targeted completion of missing information based on user preferences. We can also describe the desired image quality through text, further enhancing the perceptual quality of the output.
Inference: LLaVA takes the degradation-robust processed LQ images as input and explicitly understands the content within the images, outputting in the form of textual descriptions. These descriptions are then used as prompts to guide the restoration.
Training: we also collect textual annotations for all the training images, to reinforce the role of textual control during the training of out model.
Negative-Quality Samples and Prompt.
Adjust the negative prompt in CFG
In our framework, pos can be the image description with positive words of quality, and neg is the negative words of quality. Therefore, using negative-quality prompts during sampling may introduce artifacts, see Fig. 4 for an example.
However, the absence of negative-quality samples and prompts in our training data may lead to a failure of the fine-tuned SUPIR in understanding negative prompts. To address this problem, we used SDXL to generate 100K images corresponding to the negative-quality prompts. We counterintuitively add these low-quality images to the training data to ensure that negative-quality concept can be learned by the proposed SUPIR model.
Restoration-Guided Sampling
- Problem: We need means to limit the generation to ensure that the image recovery is faithful to the LQ image.
- Solution: We modified the EDM sampling method [41]
and proposed a restoration-guided sampling method to
solve this problem.
- We hope to selectively guide the prediction results \(z_{t−1}\) to be close to the LQ image \(z_{LQ}\) in each diffusion step. The specific algorithm is shown in Algorithm 1, where \(T\) is the total step number, \(\left\{\sigma_t\right\}_{t=1}^T\) are the noise variance for \(T\) steps, \(c\) is the additional text prompt condition. \(\tau_r, S_{\text {churn }}, S_{\text {noise }}, S_{\text {min }}, S_{\text {max }}\) are five hyper-parameters, but only \(\tau_r\) is related to the restoration guidance, the others remain unchanged compared to the original EDM method [41]. For better understanding, a simple diagram is shown in Fig. 5(b). We perform weighted interpolation between the predicted output \(\hat{z}_{t-1}\) and the LQ latent \(z_{L Q}\) as the restoration-guided output \(z_{t-1}\). Since the low-frequency information of the image is mainly generated in the early stage of diffusion prediction [65] (where \(t\) and \(\sigma_t\) are relatively large, and the weight \(k=\left(\sigma_t / \sigma_T\right)^{\tau_r}\) is also large), the prediction result is closer to \(z_{L Q}\) to enhance fidelity. In the later stages of diffusion prediction, mainly high-frequency details are generated. There should not be too many constraints at this time to ensure that detail and texture can be adequately generated. At this time, \(t\) and \(\sigma_t\) are relatively small, and weight \(k\) is also small. Therefore, the predicted results will not be greatly affected Through this method, we can control the generation during the diffusion sampling process to ensure fidelity.
<img src="https://minio.yixingfu.net/blog/2024-12-30/9c9329bf109255626c8935b70fec387541972287906a5abfe1d46e2714c16e2d.png", width="60%"<img src="https://minio.yixingfu.net/blog/2024-12-30/374edbc2973b0c53723c3d7b79365f62baf8a408523fb3a3be12695cbb15c048.png", width="60%"Experiments
Settings
- The overall training data includes:
- 20 million high-quality images with text descriptions
- 70 K face images and 100 K negative-quality samples, together their corresponding prompts.
- To enable a larger batch size, we crop images into \(512 \times 512\) patches during training.
- We train our model using a synthetic degradation model, following the setting used by Real-ESRGAN [78], the only difference is that we resize the produced LQ images to \(512 \times 512\) for training.
- We use the
AdamWoptimizer [53] with a learning rate of0.00001. - The training process spans 10 days and is conducted on 64 Nvidia A6000 GPUs, with a batch size of 256.
- For testing, the hyper-parameters are \(T=100, \lambda_{\mathrm{cfg}}=7.5\), and \(\tau_r=4\). Our method is able to process images with the size of \(1024 \times 1024\). We resize the short side of the input image to 1024 and crop a \(1024 \times 1024\) sub-image for testing, and then resize it back to the original size after restoration. Unless stated otherwise, prompts will not be provided manually - the processing will be entirely automatic.
Comparison with existing IR methods
We conduct comparisons on both synthetic data and real-world data.
Synthetic Data:
- Methods:
- BSRGAN [90]
- Real-ESRGAN [78]
- StableSR [75]
- DiffBIR [49] and PASD [85].
- Metrics:
- Full-reference metrics: PSNR, SSIM, LPIPS
- Non-reference metrics: ManIQA, ClipIQA, MUSIQ
- Conclusion:
- It can be seen that our method achieves the best results on all non-reference metrics, which reflects the excellent image quality of our results
- At the same time, we also note the disadvantages of our method in full-reference metrics. We present a simple experiment that highlights the limitations of these full-reference metrics. It can be seen that our results have better visual effects, but they do not have an advantage in these metrics. This phenomenon has also been noted in many studies as well [6, 26, 28].
<img src="https://minio.yixingfu.net/blog/2024-12-30/32ef332a30947b3d8137438c903998c3293352223b3b66fdb0eda631af2013fd.png", width="60%"Restoration in the Wild
- Data: We collect a total of 60 real-world LQ images from RealSR [8], DRealSR [80], Real47 [49], and online sources, featuring diverse content including animals, plants, faces, buildings, and landscapes. We show the qualitative results in Fig. 10, and the quantitative results are shown in Tab. 2a.
- Conclusion: our method have the best perceptual quality.
<img src="https://minio.yixingfu.net/blog/2024-12-30/928451b75f6388c2eaaadf0d2e972df8d915aa656c4f4cd2abe38ada965e3a36.png", width="60%"
Controlling Restoration with Textual Prompts
- Capabilities: After training on a large dataset of image-text pairs and leveraging the feature of the diffusion model, our method can selectively restore images based on human prompts. In addition to prompting the image content, we can also prompt the model to generate higher-quality images through negative-quality prompts.
- Limitations: We also observed that prompts in our method are not always effective. When the provided prompts do not align with the LQ image, the prompts become ineffective.
Ablation Study
Connector: We compare the proposed
ZeroSFTconnector with zero convolution [92]. Quantitative results are shown in Tab. 2c. Compared toZeroSFT, zero convolution yields comparable performance on non-reference metrics and much lower full-reference performance.Training data scaling: We trained our large-scale model on two smaller datasets for IR, DIV2K [3] and LSDIR [1]. The qualitative results are shown in Fig. 12, which clearly demonstrate the importance and necessity of training on large-scale high-quality data.
Negative-quality samples and prompt: If negative samples are not included for training, these two prompts will not be able to improve the perceptual quality.
Restoration-guided sampling method: The proposed restoration-guided sampling method is mainly controlled by \(\tau_r\). The larger \(\tau_r\) is, the fewer corrections are made to the generation at each step. The smaller \(\tau_r\) is, the more generated content will be forced to be closer to the LQ image. We choose \(\tau_r=4\) as the default parameter, as it doesn't compromise image quality while effectively enhancing fidelity.
<img src="https://minio.yixingfu.net/blog/2024-12-31/23394cc4c88df8efbacce5ff70e6c4e36d68cf443a5c7227d3b93692ffc01475.png", width="60%"Conclusion
We propose SUPIR as a pioneering IR method, empowered by model scaling, dataset enrichment, and advanced design features, expanding the horizons of IR with enhanced perceptual quality and controlled textual prompts.