One prompt one story
Abstract
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities. We then refine the generation process using two novel techniques: Singular-Value Reweighting and Identity-Preserving Cross-Attention, ensuring better alignment with the input description for each frame.
Introduction
JeDi: Joint-Image Diffusion Models for Finetuning-Free Personalized Text-to-Image Generation
However, achieving consistent T2I generation remains a challenge for existing models, as shown in Fig. 1 (up).
training method
- Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models
- Svdiff: Compact parameter space for diffusion fine-tuning.
- CustomDiffusion
- Multi-concept customization of text-to-image diffusion.
- VeRA: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Representations, 2024
Dreambooth [28] finetunes the entire model weights on the reference set, with a loss on images of similar concepts as regularization. CustomDiffusion [16] optimizes only a few parameters to enable fast tuning, and combines multiple finetuned models for multi-concept personalization. Textual Inversion [10] projects the reference images onto the text embedding space through an optimization process. SVDiff [11] finetunes only the singular values of the weight matrices to reduce the risk of overfitting. These finetuning-based methods require a substantial amount of resources and long training time, and often need multiple reference images per custom subject.
training free methods:
- Training-free consistent text-to-image generation [Constory]
- Storydiffusion: Consistent self-attention for long-range image and video generation
- Joint-image diffusion models for finetuning-free personalized text-to-image generation
comparing methods
- Constory
- Storydiffusion
- IP-Adapter
they all neglect the inherent property of long prompts that identity information is implicitly maintained by context understanding, which we refer to as the context consistency of language models. We take advantage of this inherent feature to eliminate the requirement of additional finetuning or complicated module design.
Specifically, 1Prompt1Story consolidates all desired prompts into a single longer sentence, which starts with an identity prompt that describes the corresponding identity attributes and continues with subsequent frame prompts describing the desired scenarios in each frame. We denote this first step as prompts consolidation. By reweighting the consolidated prompt embeddings, we can easily implement a basic method Naive Prompt Reweighting to adjust the T2I generation performance, and this approach inherently achieves excellent identity consistency.
However, this basic approach does not guarantee strong text-image alignment for each frame, as the semantics of each frame prompt are usually intertwined within the consolidated prompt embedding.
To further enhance text-image alignment and identity consistency of the T2I generative models, we introduce two additional techniques: Singular-Value Reweighting (SVR) and Identity-Preserving Cross-Attention (IPCA). The Singular-Value Reweighting aims to refine the expression of the prompt of the current frame while attenuating the information from the other frames. Meanwhile, the strategy Identity-Preserving Cross-Attention strengthens the consistency of the subject in the cross-attention layers. By applying our proposed techniques, 1Prompt1Story achieves more consistent T2I generation results compared to existing approaches.
Contributions:
- To the best of our knowledge, we are the first to analyze the overlooked ability of language models to maintain inherent context consistency, where multiple frame descriptions within a single prompt inherently refer to the same subject identity.
- Based on the context consistency property, we propose One-Prompt-One-Story as a novel training free method for consistent T2I generation. More specifically, we further propose Singular-Value Reweighting and Identity-Preserving Cross-Attention techniques to improve text-image alignment and subject consistency, allowing each frame prompt to be individually expressed within a single prompt while maintaining a consistent identity along with the identity prompt.
- Through extensive comparisons with existing consistent T2I generation approaches, we confirm the effectiveness of 1Prompt1Story in generating images that consistently maintain identity throughout a lengthy narrative over our extended ConsiStory+ benchmark.
Related Work
T2I personalized generation.
T2I personalization is also referred to T2I model adaptation. This aims to adapt a given model to a new concept by providing a few images and binding the new concept to a unique token. As a result, the adaptation model can generate various renditions of the new concept. One of the most representative methods is DreamBooth (Ruiz et al., 2023), where the pre-trained T2I model learns to bind a modified unique identifier to a specific subject given a few images, while it also updates the T2I model parameters.
Recent approaches (Kumari et al., 2023; Han et al., 2023b; Shi et al., 2023) follow this pipeline and further improve the quality of the generation. Textual Inversion (Gal et al., 2023a), focuses on learning new concept tokens instead of fine-tuning the T2I generative models.
Consistent T2I generation.
They mainly take advantage of PEFT techniques or pre-training with large datasets to learn the image encoder to be customized in the semantic space.
However, most consistent T2I generation methods still require training the parameters of the T2I models, sacrificing compatibility with existing pretrained community models, or fail to ensure high face fidelity. Additionally, as most of these systems (Li et al., 2023b; Gal et al., 2023b; Ruiz et al., 2024) are designed specifically for human faces, they encounter limitations when applied to non-human subjects. Even for the state-of-the-art approaches, including StoryDiffusion (Zhou et al., 2024), The Chosen One (Avrahami et al., 2023) and ConsiStory (Tewel et al., 2024), they either require time-consuming iterative clustering or high memory demand in generation to achieve identity consistency.
Method
Context Consistency
This property stems from the self-attention mechanism within Transformer-based text encoders (Radford et al., 2021; Vaswani et al., 2017), which allows learning the interaction between phrases in the text embedding space. Previous consistent T2I generation works (Avrahami et al., 2023; Tewel et al., 2024; Zhou et al., 2024) generate images from a set of N prompts. This set of prompts starts with an identity prompt P0 that describes the relevant attribute of the subject and continues with multiple frame prompt Pi , where i = 1, . . . , N describes each frame scenario. [The chosen one, Training-Free Consistent Text-to-Image Generation, STORYDIFFUSION]
However, this separate generation pipeline ignores the inherent language property, i.e., the context consistency, by which identity is consistently ensured by the context information inherent in language models. This property stems from the self-attention mechanism within Transformer-based text encoders (Radford et al., 2021; Vaswani et al., 2017), which allows learning the interaction between phrases in the text embedding space.
In the following, we analyze the context consistency under different prompt configurations in both textual space and image space. Specifically, we refer to the conventional prompt setups as multi prompt generation, which is commonly used in existing consistent T2I generation methods. The multi-prompt generation uses \(N\) prompts separately for each generated frame, each sharing the same identity prompt and the corresponding frame prompt as \(\left[\mathcal{P}_0 ; \mathcal{P}_i\right], i \in[1, N]\). In contrast, our single prompt generation concatenates all the prompts as \(\left[\mathcal{P}_0 ; \mathcal{P}_1 ; \ldots ; \mathcal{P}_N\right]\) for each frame generation, which we refer as the Prompt Consolidation (PCon).
by generate the prompt embedding in a single time, the distance are closer
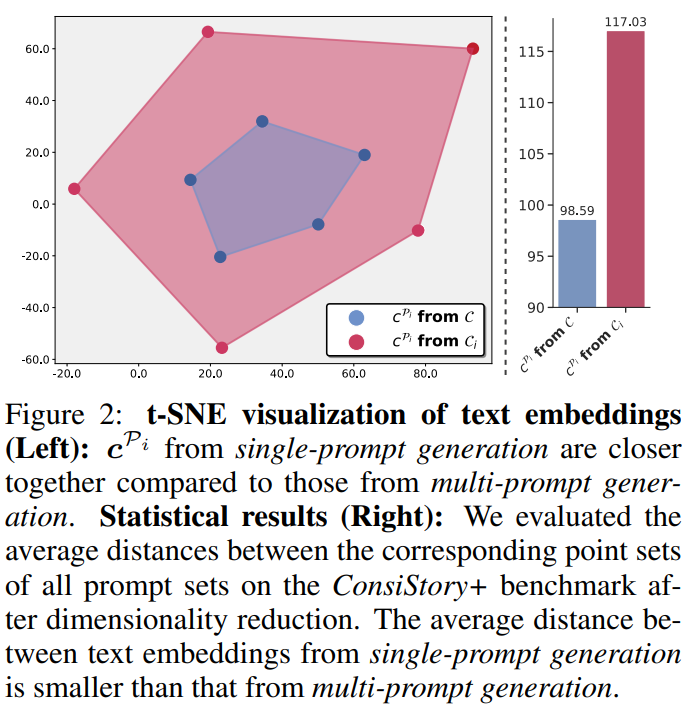
Instead, we use our proposed concatenated prompt \(\mathcal{P}=\) \(\left[\mathcal{P}_0 ; \mathcal{P}_1 ; \ldots ; \mathcal{P}_N\right]\). To generate the \(i\)-th frame \((i=1, \ldots, N)\), we reweight the \(\boldsymbol{c}^{\mathcal{P}_i}\) corresponding to the desired frame prompt \(\mathcal{P}_i\) by a magnification factor while rescaling the embeddings of the other frame prompts by a reduction factor. This modified text embedding is then imported to the T2I model to generate the frame image. We refer to this simplistic reweighting approach as Naive Prompt Reweighting (NPR). By this means, the T2I model synthesizes frame images with the same subject identity. However, the backgrounds get blended among these frames, as shown in Fig. 3
one prompt one story
Naive Prompt Reweighting cannot guarantee that the generated images accurately reflect the frame prompt descriptions. Furthermore, the various semantics within the consolidated descriptions interact with each other
- Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models
- Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment
EOT token contains significant semantic information:
- Relation Rectification in Diffusion Model
- Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models
To mitigate this issue, we propose additional techniques based on the Prompt Consolidation (PCon), namely Singular-Value Reweighting (SVR) and Identity-Preserving Cross-Attention (IPCA).
Singular-Value Reweighting.
After the Prompt Consolidation as \(\mathcal{C}=\tau_{\xi}\left(\left[\mathcal{P}_0 ; \mathcal{P}_1 ; \ldots ; \mathcal{P}_N\right]\right)=\) \(\left[\boldsymbol{c}^{S O T}, \boldsymbol{c}^{\mathcal{P}_0}, \boldsymbol{c}^{\mathcal{P}_1}, \ldots, \boldsymbol{c}^{\mathcal{P}_N}, \boldsymbol{c}^{E O T}\right]\), we require the current frame prompt to be better expressed in the T2I generation, which we denote as \(\mathcal{P}^{e x p}=\mathcal{P}_j,(j=1, \ldots, N)\). We also expect the remaining frames to be suppressed in the generation, which we denote as \(\mathcal{P}^{s u p}=\mathcal{P}_k, k \in[1, N] \backslash\{j\}\). Thus, the \(N\) frame prompts of the subject description can be written as \(\left\{\mathcal{P}^{e x p}, \mathcal{P}^{s u p}\right\}\). As the [EOT] token contains significant semantic information (Li et al., 2023a; Wu et al., 2024b), the semantic information corresponding to \(\mathcal{P}^{e x p}\), in both \(\mathcal{P}_j\) and [EOT], needs to be enhanced, while the semantic information corresponding to \(\mathcal{P}^{s u p}\), in \(\mathcal{P}_k, k \neq j\) and [EOT], need to be suppressed. We extract the token embeddings for both express and suppress sets as \(\mathcal{X}^{\exp }=\left[\boldsymbol{c}^{\mathcal{P}_j}, \boldsymbol{c}^{E O T}\right]\) and \(\mathcal{X}^{\text {sup }}=\) \(\left[\boldsymbol{c}^{\mathcal{P}_1}, \ldots, \boldsymbol{c}^{\mathcal{P}_{j-1}}, \boldsymbol{c}^{\mathcal{P}_{j+1}}, \ldots, \boldsymbol{c}^{\mathcal{P}_N}, \boldsymbol{c}^{E O T}\right]\). Inspired by (Gu et al., 2014; Li et al., 2023a), we assume that the main singular values of \(\mathcal{X}^{\exp }\) correspond to the fundamental information of \(\mathcal{P}^{e x p}\). We then perform SVD decomposition as: \(\mathcal{X}^{\exp }=\boldsymbol{U} \boldsymbol{\Sigma} \boldsymbol{V}^T\), where \(\boldsymbol{\Sigma}=\operatorname{diag}\left(\sigma_0, \sigma_1, \cdots, \sigma_{n_j}\right)\), the singular values \(\boldsymbol{\sigma}_0 \geq \cdots \geq \boldsymbol{\sigma}_{n_j}{ }^2\). To enhance the expression of the frame \(\mathcal{P}_j\), we introduce the augmentation for each singular value, termed as SVR+ and formulated as: \[ \hat{\sigma}=\beta e^{\alpha \sigma} * \sigma \]
where the symbol \(e\) is the exponential, \(\alpha\) and \(\beta\) are parameters with positive numbers. We recover the tokens as \(\hat{\mathcal{X}}{ }^{e x p}=\boldsymbol{U} \hat{\boldsymbol{\Sigma}} \boldsymbol{V}^T\), with the updated \(\hat{\boldsymbol{\Sigma}}=\operatorname{diag}\left(\hat{\sigma_0}, \hat{\sigma_1}, \cdots, \hat{\sigma}_{n_j}\right)\). The new prompt embedding is defined as \(\hat{\mathcal{X}}^{e x p}=\left[\hat{\boldsymbol{c}}^{\mathcal{P}_j}, \hat{\boldsymbol{c}}^{E O T}\right]\), and \(\hat{\mathcal{C}}=\left[\boldsymbol{c}^{S O T}, \boldsymbol{c}^{\mathcal{P}_0}, \cdots, \hat{\boldsymbol{c}}^{\mathcal{P}_j}, \cdots, \boldsymbol{c}^{\mathcal{P}_N}, \hat{\boldsymbol{c}}^{E O T}\right]\). Note that there is an updated \(\hat{\mathcal{X}}^{s u p}=\left[\boldsymbol{c}^{\mathcal{P}_1}, \ldots, \boldsymbol{c}^{\mathcal{P}_{j-1}}, \boldsymbol{c}^{\mathcal{P}_{j+1}}, \ldots, \boldsymbol{c}^{\mathcal{P}_N}, \hat{\boldsymbol{c}}^{E O T}\right]\).
Appendix of Fig. 11 -right). Therefore, we propose to weaken each frame prompt in \(\hat{\mathcal{X}}^{\text {sup }}\) separately. We construct the matrix as \(\hat{\mathcal{X}}_k^{\text {sup }}=\left[\boldsymbol{c}^{\mathcal{P}_k}, \hat{\boldsymbol{c}}^{E O T}\right], k \neq j\) to perform SVD with the singular values \(\hat{\boldsymbol{\sigma}}_0 \geq \cdots \geq \hat{\boldsymbol{\sigma}}_{n_k}\). Then, each singular value is weakened as follows, termed as SVR-:
\[ \tilde{\sigma}=\beta^{\prime} e^{-\alpha^{\prime} \hat{\sigma}} * \hat{\sigma} \]
where \(\alpha^{\prime}\) and \(\beta^{\prime}\) are parameters with positive numbers. The recovered structure is \(\tilde{\mathcal{X}}_k^{\text {sup }}=\) \(\left[\tilde{\boldsymbol{c}}^{\mathcal{P}_k}, \tilde{\boldsymbol{c}}^{E O T}\right]\), After reducing the expression of each suppress token, we finally obtain the new text embedding \(\tilde{\mathcal{C}}=\left[\boldsymbol{c}^{S O T}, \boldsymbol{c}^{\mathcal{P}_0}, \tilde{\boldsymbol{c}}^{\mathcal{P}_1}, \cdots, \hat{\boldsymbol{c}}^{\mathcal{P}_j}, \cdots, \tilde{\boldsymbol{c}}^{\mathcal{P}_N}, \tilde{\boldsymbol{c}}^{E O T}\right]\).
Identity-Preserving Cross-Attention
Recent work (Liu et al., 2024) demonstrated that cross-attention maps capture the characteristic information of the token, while self-attention preserves the layout information and the shape details of the image.
- Towards understanding cross and self-attention in stable diffusion for text-guided image editing
Inspired by this, we propose Identity-Preserving Cross-Attention to further enhance the identity similarity between images generated from the concatenated prompt of our proposed Prompt Consolidation.
Experiments
Qualitative Comparison.
Additionally, IP-Adapter tends to generate images with repetitive poses and similar backgrounds, often neglecting frame prompt descriptions.
Quantitative Comparison.
In Table 1, we illustrate the quantitative comparison with other approaches. In all evaluation metrics, 1Prompt1Story ranks first among the training-free methods, and second when including training-required methods.