PuLid
Introduces both contrastive alignment loss and accurate ID loss to keep ID fidelity.
Abstract
For ID custimization, two branches
- fine-tunes certain parameters:
- Textual Inversion
- Dreambooth
- Lora
- Multi-Concept Customization of Text-to-Image Diffusion
- Forgoes fine-tuning for each ID:
- Tuning-free multi-subject image generation with localized attention
- IP-Adapter
- Photoverse
- Face0: Instantaneously conditioning a text-to-image model on a face.
- Photomaker
- When stylegan meets stable diffusion: a w plus adapter for personalized image generation.
- Instantid
Introduction
Current Challenges
Insertion of ID disrupts the original model’s behavior
Only altering ID-related aspects. While IP-Adapter, Instantid, Photomaker has shown the ability for stylized ID generation, notable style degradation occurs when compared with images before ID insertion.
Retain the ability of the original T2I model to follow prompts.
- Enhancing the encoder: IP-Adapter faceid shift from CLIP extraction to Face ID by Arcface to extract more abstract and relevant ID information.(the paper says the ID fidelity is not high enough) InstantID includes an additional ID&Landmark ControlNet for more effective modulation.(compromises some degree of editability and flexibility)
- Photomaker constructing datasets grouped by ID; each ID includes several images.(demands significant effort, effects to non-celebrities may be limited)
Lack of ID fidelity
Introduce ID loss within diffusion training: Due to the iterative denoising nature of diffusion models, achieving an accurate x0 needs multiple steps.
predict x0 directly from the current timestep and then calculate the ID loss: when the current timestep is large, the predicted x0 is often noisy and flawed.
PortraitBooth calculates ID loss only at less noisy timesteps: ignores such loss in the early steps, thereby limiting its overall effectiveness
Proposal
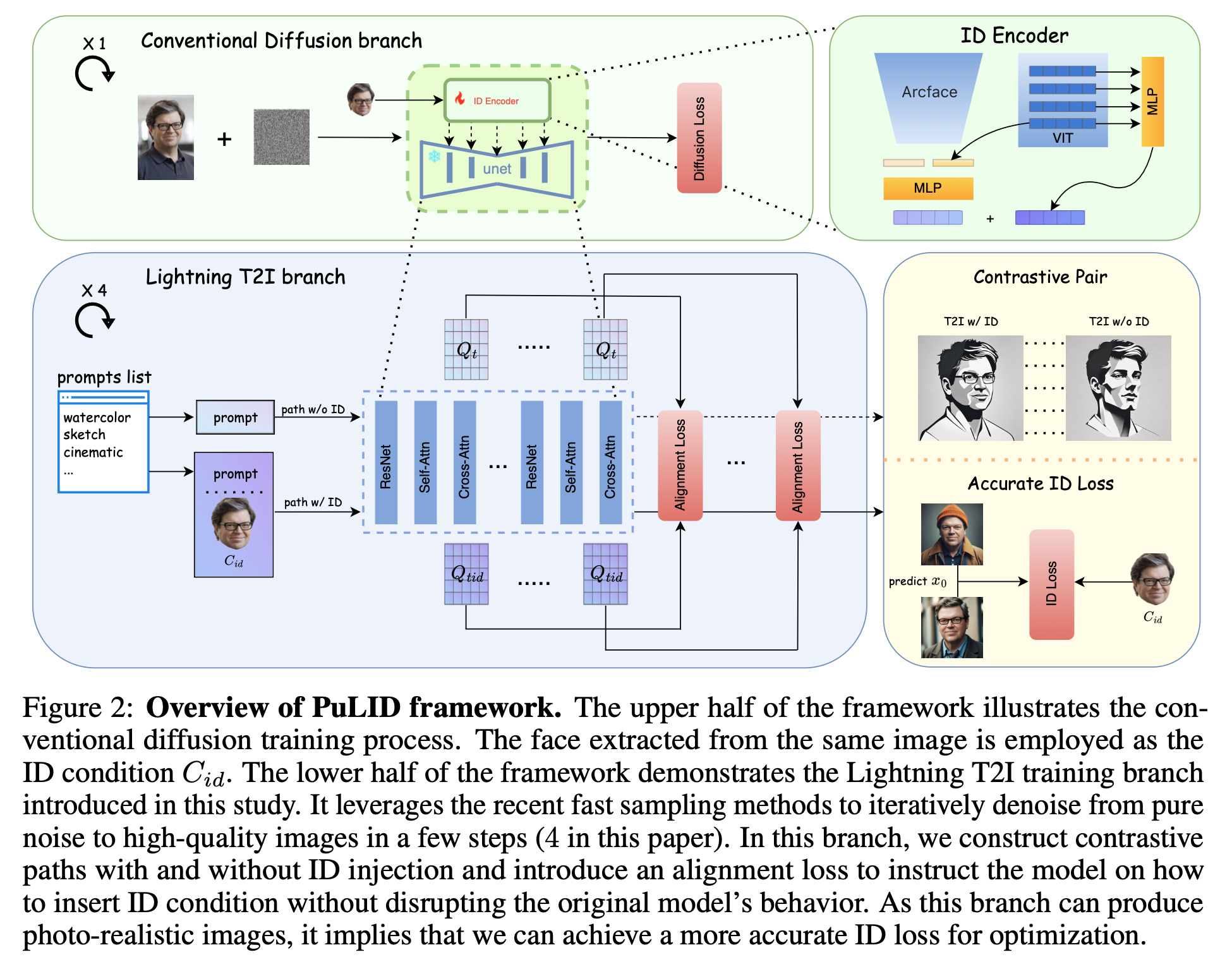
introduce a Lightning T2I branch alongside the standard diffusion-denoising training branch. the lighting T2I branch can generate high-quality images from pure noise with a limited and manageable number of steps.
- minimize the influence on the original model’s behavior
- naturally extract its face embedding and calculate an accurate ID loss
Contributions
We propose a tuning-free method, namely, PuLID, which preserves high ID similarity while mitigating the impact on the original model’s behavior.
We introduce a Lightning T2I branch alongside the regular diffusion branch. Within this branch, we incorporate a contrastive alignment loss and ID loss to minimize the contamination of ID information on the original model while ensuring fidelity. Compared to the current mainstream approaches that improve the ID encoder or datasets, we offer a new perspective and training paradigm.
Experiments show that our method achieves SOTA performance in terms of both ID fidelity and editability. Moreover, compared to existing methods, our ID information is less invasive to the model, making our method more flexible for practical applications.
Related work
Notably, models with higher ID fidelity often cause more significant disruptions to the behavior of the original model.
advanced sampling methods: DDIM, DPM-solver++, DPS
- Recent distill-based works:
- Progressive adversarial diffusion distillation.
- Latent consistency models: Synthesizing high-resolution images with few-step inference.
- Adversarial diffusion distillation
In this study, the Lightning T2I training branch we introduce leverages the SDXL-Lightning [23] acceleration technology: Sdxl-lightning: Progressive adversarial diffusion distillation.
- Recent distill-based works:
ID Loss
To improve ID fidelity, ID loss is employed in previous works [18,3], motivated by its effectiveness in prior GAN-based works [35,45]. However, in these methods, \(x_0\) is typically directly predicted from the current timestep using a single step, often resulting in noisy and flawed images. Such images are not ideal for the face recognition models [6], as they are trained on real-world images. PortraitBooth [29] alleviates this issue by only applying ID loss at less noisy stages, which ignores such loss in the early steps, thereby limiting its overall effectiveness. Diffswap [54] obtains a better predicted \(x_0\) by employing two steps instead of just one, even though this estimation still contains noisy artifacts. In our work, with the introduced Lightning T2I training branch, we can calculate ID loss in a more accurate setting.
Basic setting
Currently, tuning-free ID customization methods generally face a challenge: the embedding of the ID disrupts the behavior of the original model.
In conventional ID Customization diffusion training process, as formulated in Eq. 1, the ID condition Cid is usually cropped from the target image x0 [50, 44]. In this scenario, the ID condition aligns completely with the prompt and UNET features, implying the ID condition does not constitute contamination to the T2I diffusion model during the training process. This essentially forms a reconstruction training task. So, to better reconstruct x0 (or predict noise ϵ), the model will make the utmost effort to use all the information from ID features (which may likely contain ID-irrelevant information), as well as bias the training parameters towards the dataset distribution, typically in the realistic portrait domain. Consequently, during testing, when we provide a prompt that is in conflict or misaligned with the ID condition, such as altering ID attributes or changing styles, these methods tend to fail. This is because there exists a disparity between the testing and training settings.
- ID insert way: ip-adapter
- Embeding: faceid and clip image embeds concatenate and use MLP to map them into 5 tokens.
- Contrastive Alignment: One path is conditioned only by the prompt, while the other path employs both the ID and the prompt as conditions.
Loss
Alignment Loss
the response region of attention mask aplied to Q should remain the same with and without ID.
semantic alignment loss: can be interpreted as the response of the UNET features to the prompt. If the embedding of ID does not affect the original model’s behavior, then the response of the UNET features to the prompt should be similar in both paths \[ \mathcal{L}_{\text {align-sem }}=\left\|\operatorname{Softmax}\left(\frac{K Q_{\text {tid }}^T}{\sqrt{d}}\right) Q_{\text {tid }}-\operatorname{Softmax}\left(\frac{K Q_t^T}{\sqrt{d}}\right) Q_t\right\|_2 \]
layout alignment loss: \[ \mathcal{L}_{\text {align-layout }}=\left\|Q_{\text {tid }}-Q_t\right\|_2 . \]
add together \[ \mathcal{L}_{\text {align }}=\lambda_{\text {align-sem }} \mathcal{L}_{\text {align-sem }}+\lambda_{\text {align-layout }} \mathcal{L}_{\text {align-layout }}, \]
ID Loss
Directly predict \(x_0\) using a single step from \(\epsilon\) will produce a flawed noisy image, will make ID loss inaccurate.
In this study, thanks to the introduced Lightning T2I branch, the above issue can be fundamentally resolved. Firstly, we can swiftly generate an accurate \(x_0\) conditioned on the ID from pure noise within 4 steps. \[ \mathcal{L}_{\text {id }}=1-\operatorname{CosSim}\left(\phi\left(C_{i d}\right), \phi\left(\operatorname{L}-\mathrm{T2I}\left(x_T, C_{i d}, C_{t x t}\right)\right)\right), \]
Total Loss \[ \mathcal{L}=\mathcal{L}_{\text {diff }}+\mathcal{L}_{\text {align }}+\lambda_{\text {id }} \mathcal{L}_{\text {id }} . \]
Experiments
ID encoder: antelopev2
CLIP Image encoder: EVA-CLIP
Dataset: BLIP-2
Training process
- In the first stage, we use the conventional diffusion loss \(L_{diff}\) to train the model.
- we resume from the first stage model and train with the ID loss \(L_{id}\) and \(L_{diff}\)
- add the alignment loss \(L_{align}\)
test set: Unsplash-50
Comparison
when compared to SOTA methods such as IPAdapter and InstantID, our PuLID tends to achieve higher ID fidelity while creating less disruption to the original model.
disruption to the model decreases, accurately replicate the lighting (1st column), style (4th column), and even layout (5th column) of the original model.
possesses respectable prompt-editing capabilities
Limitaion
- demands more CUDA memory
- ID loss impacts image quality to some extent, such as causing blurriness in faces
Source code
Get ID Embedding
Use antelopev2 to get id embedding
1 | image_bgr = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) |


Parsing
when parsing, the ears are removed
1 | # using facexlib to detect and align face |


Concatenate id embedding from atelopev2 with clip embedding from vit
1 | # transform img before sending to eva-clip-vit |
1 | id_cond = torch.stack(id_cond_list, dim=1) # [1, 1, 1280] |