In-Context LoRA for diffusion transformers

Abstract
In this study, we reevaluate and streamline this framework by hypothesizing that text-to-image DiTs inherently possess in-context generation capabilities, requiring only minimal tuning to activate them. Building on this insight, we propose a remarkably simple pipeline to leverage the in-context abilities of DiTs:
- concatenate images instead of tokens
- perform joint captioning of multiple images
- apply task-specific LoRA tuning using small datasets (e.g., 20 ∼ 100 samples) instead of full parameter tuning with large datasets.
We name our models In-Context LoRA (IC-LoRA).
Introduction
In this work, we introduce a task-agnostic framework designed to adapt text-to-image models to diverse generative tasks, aiming to provide a universal solution for versatile and controllable image generation.
Our approach contrasts with GDT in the following ways:
- Image Concatenation: We concatenate a set of images into a single large image instead of concatenating attention tokens. This method is approximately equivalent to token concatenation in diffusion transformers (DiTs), disregarding differences introduced by the Variational Autoencoder (VAE) component.
- Prompt Concatenation: We merge per-image prompts into one long prompt, enabling the model to process and generate multiple images simultaneously. This differs from the GDT approach, where each image's tokens cross-attend exclusively to its text tokens.
- Minimal Fine-Tuning with Small Datasets: Instead of performing large-scale training on hundreds of thousands of samples, we fine-tune a Low-Rank Adaptation (LoRA) of the model using a small set of just \(20 \sim 100\) image sets. This approach significantly reduces the computational resources required and largely preserves the original text-to-image model's knowledge and in-context capabilities.
To support image-conditional generation, we employ a straightforward technique: we mask one or multiple images in the concatenated large image and prompt the model to inpaint them using the remaining images. We directly utilize SDEdit [Meng et al., 2021] for this purpose.
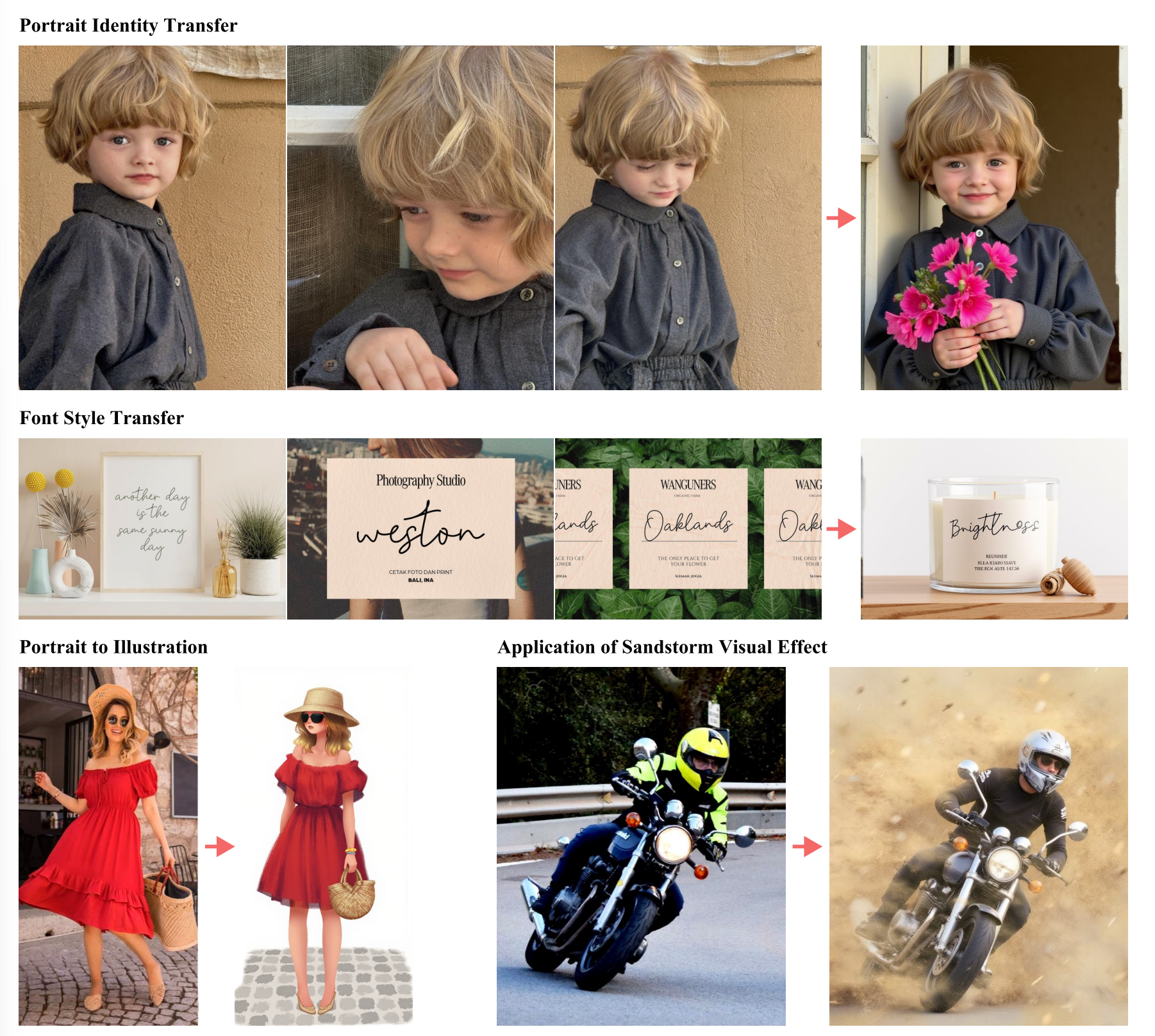
Experiments
We build our approach on the FLUX.1-dev text-to-image model [Labs, 2024] and train an In-Context LoRA specifically for our tasks. We select a range of practical tasks, including storyboard generation, font design, portrait photography, visual identity design, home decoration, visual effects, portrait illustration, and PowerPoint template design, among others. For each task, we collect 20 to 100 high-quality image sets from the internet. Each set is concatenated into a single composite image, and captions for these images are generated using Multi-modal Large Language Models (MLLMs), starting with an overall summary followed by detailed descriptions for each image. Training is conducted on a single A100 GPU for 5,000 steps with a batch size of 4 and a LoRA rank of 16 . For inference, we employ 20 sampling steps with a guidance scale of 3.5, matching the distillation guidance scale of FLUX.1-dev. For image-conditional generation, SDEdit is applied to mask images intended for generation, enabling inpainting based on the surrounding images.