Development of Unet in Diffusion Models
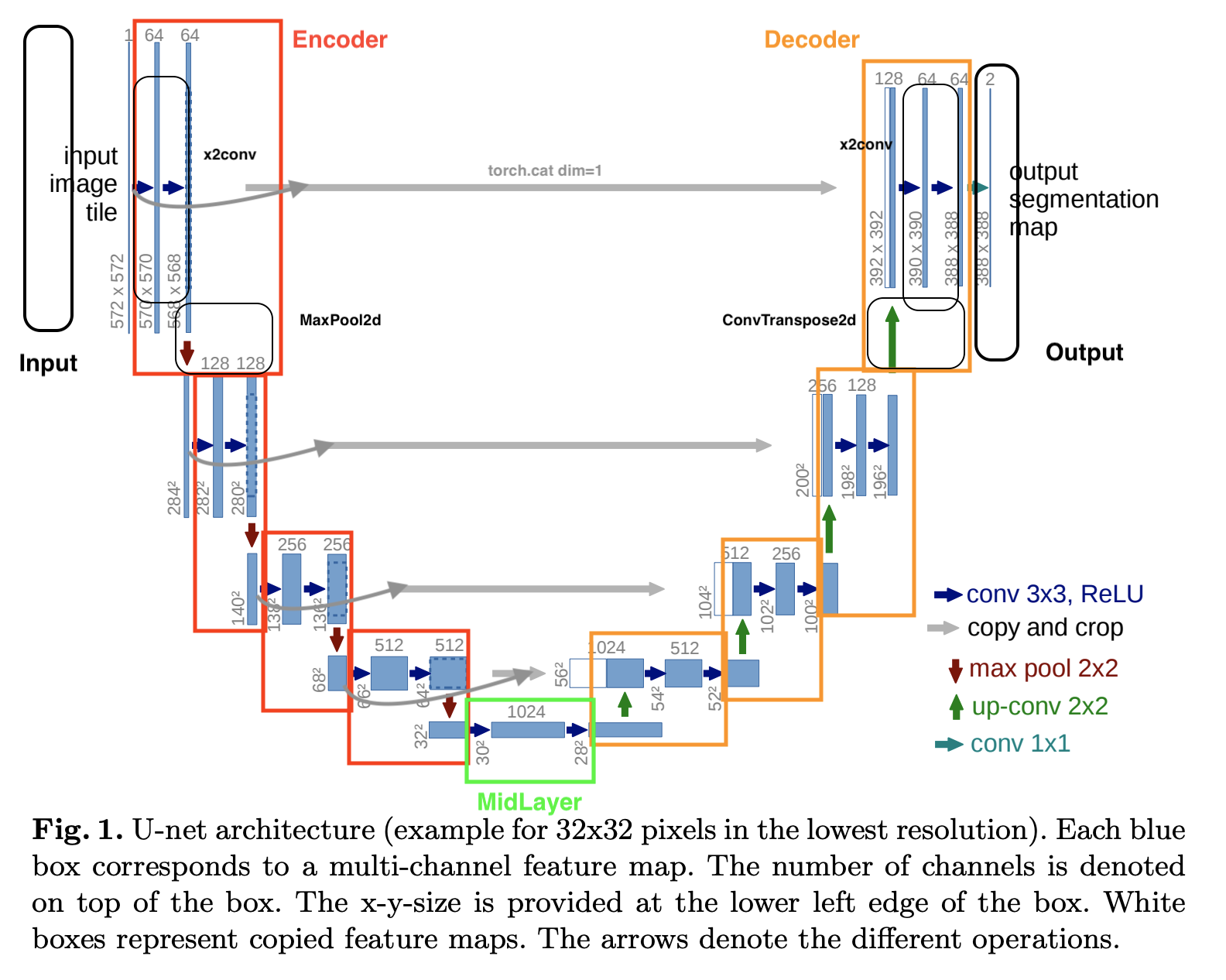
Vannila Unet
Notes
nn.ReLU(inplace=True)the ReLU activation function modifies the input data directly instead of creating a new copy of the data to store the results. So it can only be used in sequential structer since after relu, the originalxhas already been changed.
This code is not exactly the same as the original paper, but it a more modern style.
1 | from base import BaseModel |
1 | class UNet(BaseModel): |
iDDPM (DDPM)
Code
Zero Convolution
Q: If the weight of a conv layer is zero, the gradient will also be zero, and the network will not learn anything. Why "zero convolution" works? A: This is wrong. Let us consider a very simple \[ y=w x+b \] and we have \[ \partial y / \partial w=x, \partial y / \partial x=w, \partial y / \partial b=1 \] and if \(w=0\) and \(x \neq 0\), then \[ \partial y / \partial w \neq 0, \partial y / \partial x=0, \partial y / \partial b \neq 0 \] which means as long as \(x \neq 0\), one gradient descent iteration will make \(w\) non-zero. Then \[ \partial y / \partial x \neq 0 \] so that the zero convolutions will progressively become a common conv layer with non-zero weights.
At the end of self.embedding_layers and
self.out_layers , there will a zero convolution, for
example:
1 | self.out_layers = nn.Sequential( |
1 | def zero_module(module): |
since the output of self.embed add a none zero output
with self.in_layers , the gradient will backprop with no
trouble.
Scale before QKV
The comment, “More stable with f16 than dividing afterwards,” implies that multiplying the scaling factors to Q and K before computing their dot products provides more numerical stability than performing the dot product first and then dividing by a value (like the square root of the feature dimension). This is particularly true when using half-precision floating points (i.e., float16 or f16). Scaling helps prevent numerical overflow or underflow during computations. Using
einsumfor such operations effectively combines multiple steps into one, reducing cumulative errors and improving efficiency and precision.
1 | class QKVAttention(nn.Module): |
torch.einsum, originating from the Einstein Summation
Convention, is a method that provides a succinct way of expressing
multiple summations (like tensor dot products, matrix multiplication,
transposing, etc.) on tensors.
The code snippet
weight = th.einsum("bct,bcs->bts", q * scale, k * scale)
uses the torch.einsum function, which is a powerful tool
for specifying how to operate on multiple tensors.
torch.einsum, originating from the Einstein Summation
Convention, is a method that provides a succinct way of expressing
multiple summations (like tensor dot products, matrix multiplication,
transposing, etc.) on tensors.
Detailed Explanation
In the code
weight = th.einsum("bct,bcs->bts", q * scale, k * scale):
- Input tensors:
q * scaleandk * scaleare the scaled query (Q) and key (K) tensors. - einsum expression: "bct,bcs->bts" can be
interpreted as:
bctrepresents the first tensor (Q) with three dimensions:bfor batch size,cfor channels, andtfor sequence length.bcsrepresents the second tensor (K) with three dimensions:bfor batch size,cfor channels, andsfor sequence length (which can differ fromt, representing a different sequence length).-> btsindicates the dimensions of the output tensor:bfor batch size,tfrom Q’s sequence length, andsfrom K’s sequence length.
- Operation: This expression denotes that for each
batch
b, every time steptof Q is dot-producted with every time stepsof K, resulting in a tensor that sums these dot products.
Time step embedding
Vanilla Transformers
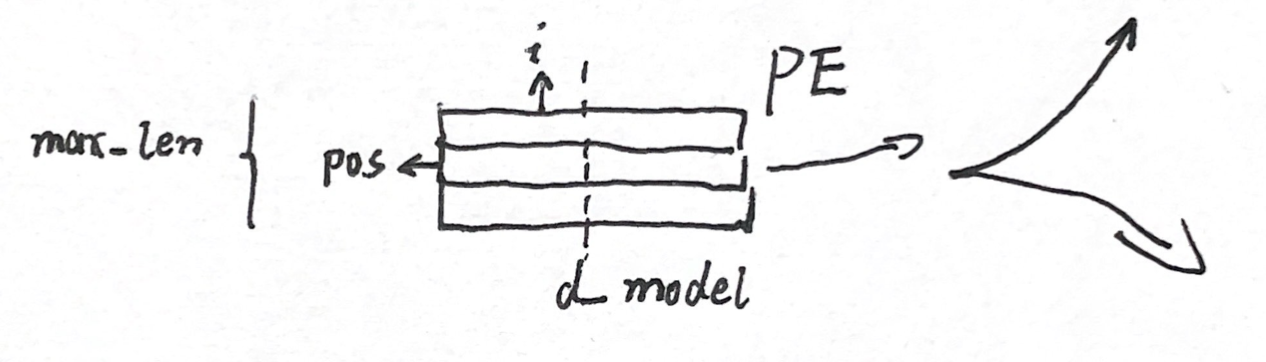
The vanilla positional encoding in transformers is: \[ \begin{aligned} P E_{(p o s, 2 i)} & =\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \\ P E_{(p o s, 2 i+1)} & =\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right)\end{aligned} \]
\[ freq = \frac{1}{10000^{\frac{2i}{d}}}=10000^{-\frac{2i}{d}}=e^{-\frac{2i}{d}log{10000}} \]
where \(PE\) is a matrix, like
below. \(POS\) is the position of on
token, and \(i\) is the index of values
in one position embedding. We can see that the value inside the
sine or cosine increases from up to down and
decreases from left to right. Therefore:
- Denominator: \([1, 10000]\)
- numerator: \([0, max\_seq\_len]\)
Since \(\frac{\pi}{2} \approx \frac{3.14}{2} = 1.57\), so at most time, the input of \(PE\) is monotonically increasing from up to down and monotonically decrease from left to right.
1 | #pytorch |
iDDPM's time step embedding
The only different part is that it puts cosine after sine, not separate consine and sine one by one line any more. \[ freq = \frac{1}{10000^{\frac{2i}{d}}}=10000^{-\frac{2i}{d}}=e^{-\frac{2i}{d}log{10000}} \]
\[ args=pos*freq \]
\[ \begin{aligned} P E_{(p o s, i)} & = \sin \left(p o s / 10000^{i / dim}\right), \cos \left(p o s / 10000^{i / dim} \right)\end{aligned} \, i \in [0, dim//2] \]
\[ \begin{aligned} P E_{(p o s, i)} & = \sin \left(p o s / 10000^{i / dim}\right), \cos \left(p o s / 10000^{i / dim} \right)\end{aligned} ,0 \; if \, i\%2 \,\; \;i \in [0, dim//2] \]
1 | def timestep_embedding(timesteps, dim, max_period=10000): |
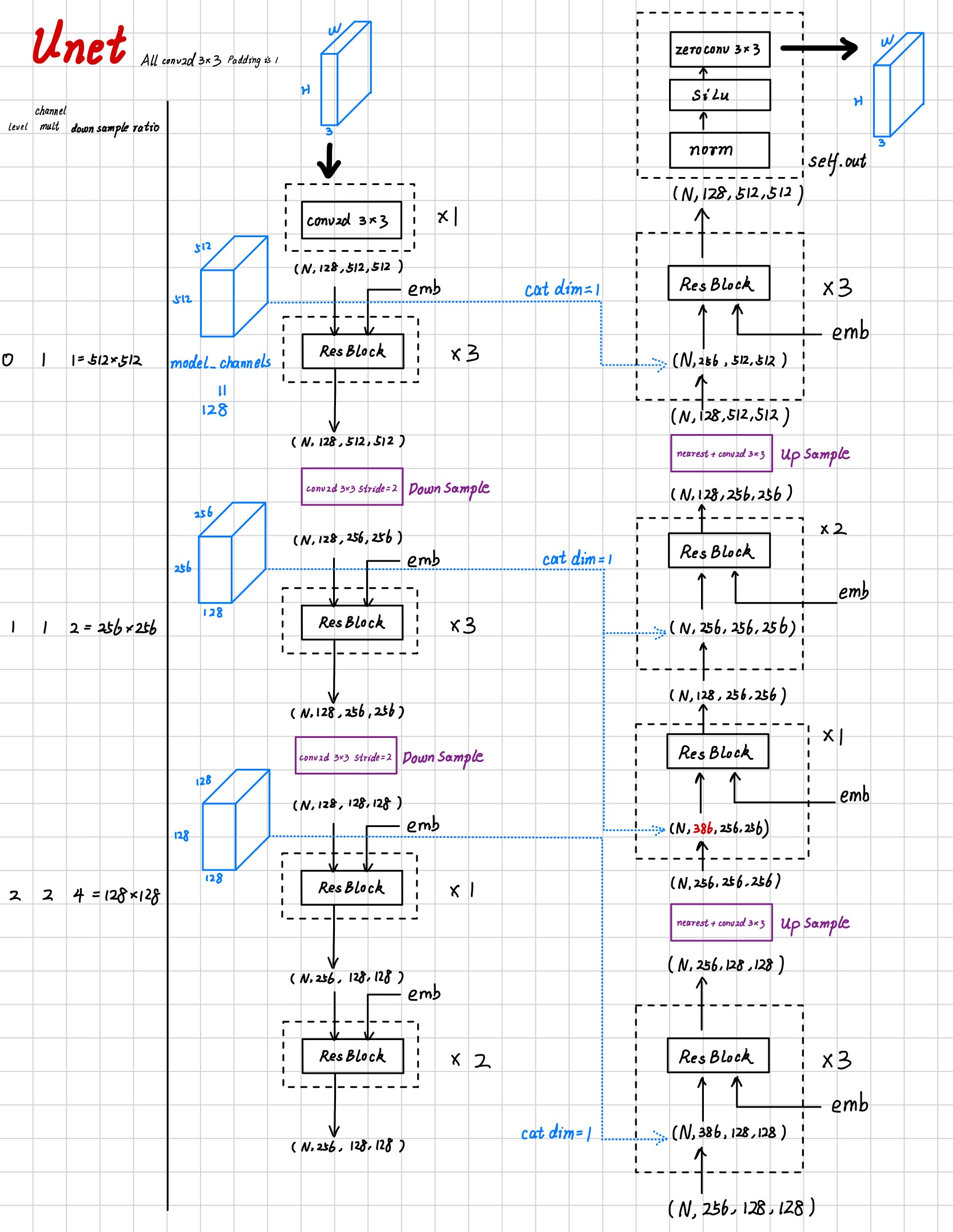
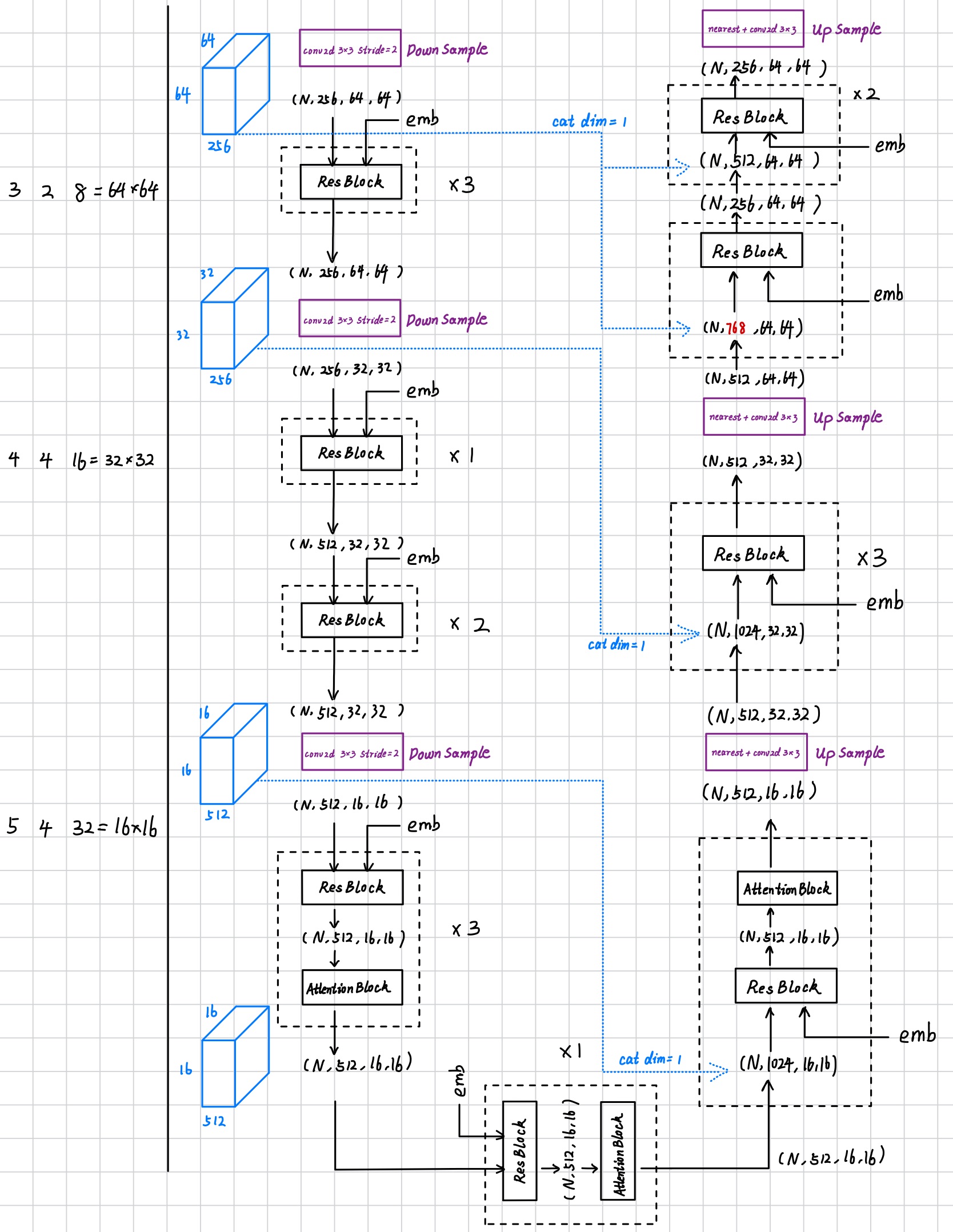
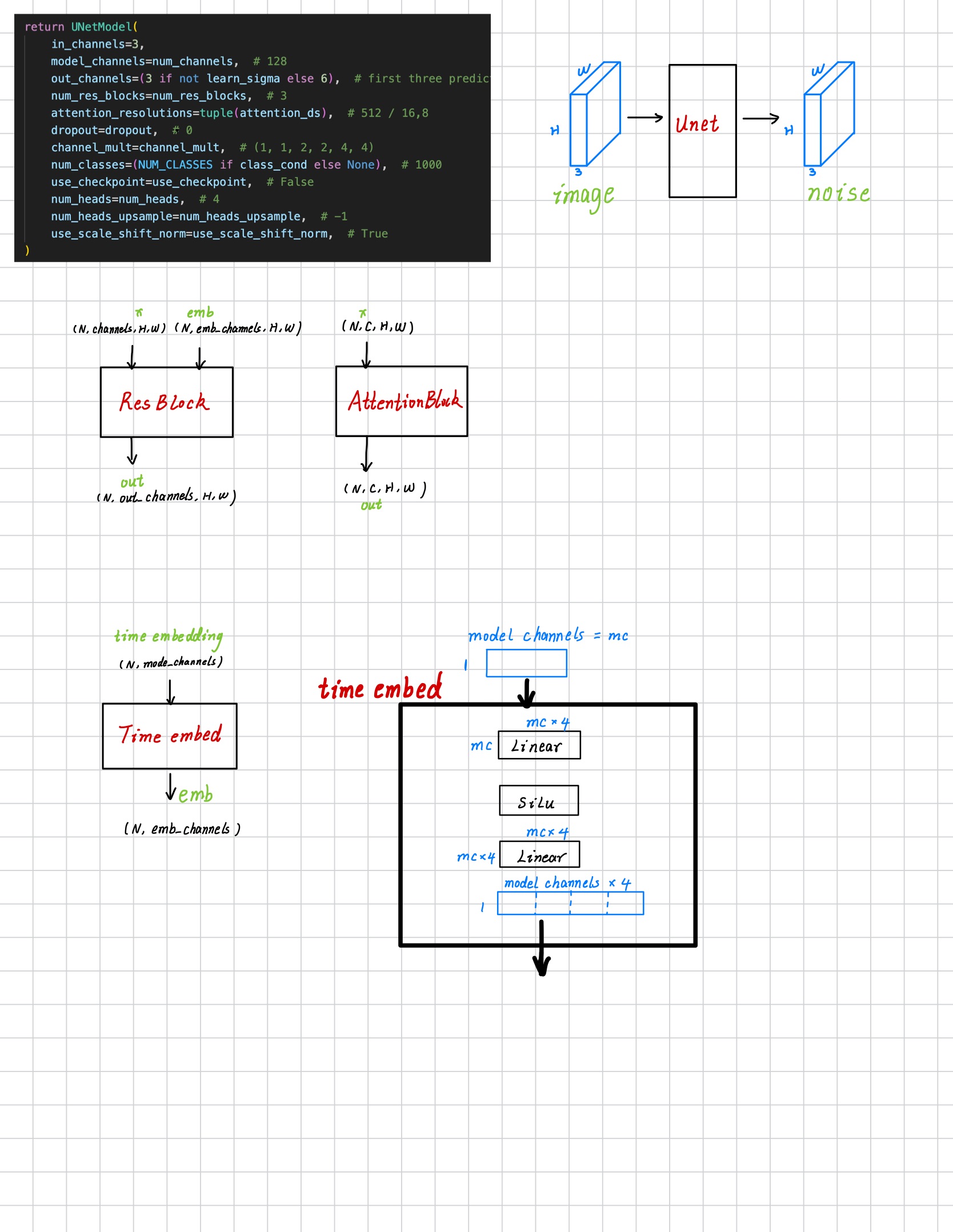
Network Figures
I hand wirte the figure about the work flow of Unet and some important blocks.
Overview & Time Embed
This time embed block is used to preprocess the time embedding rather than generating raw time embedding.
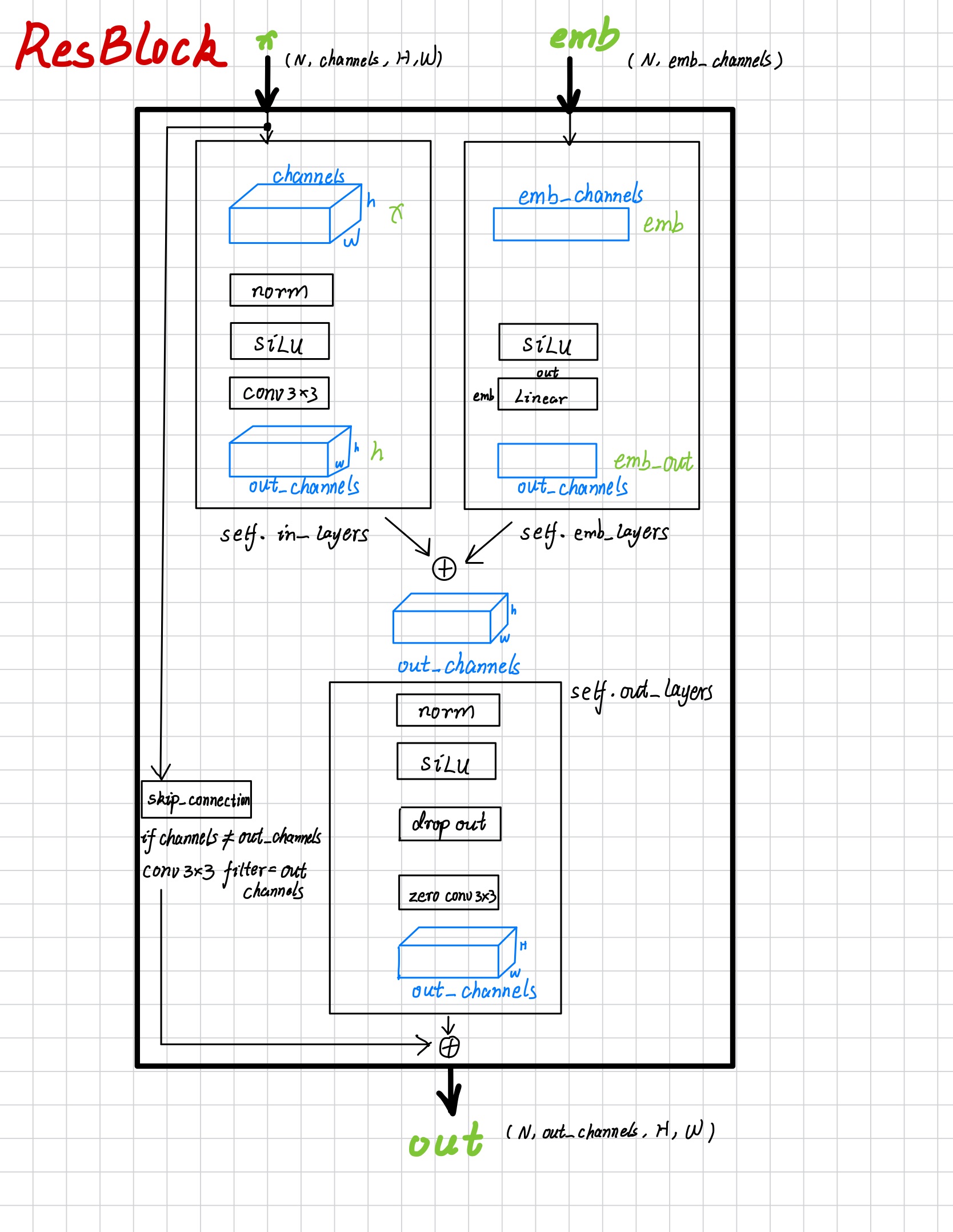
ResBlock
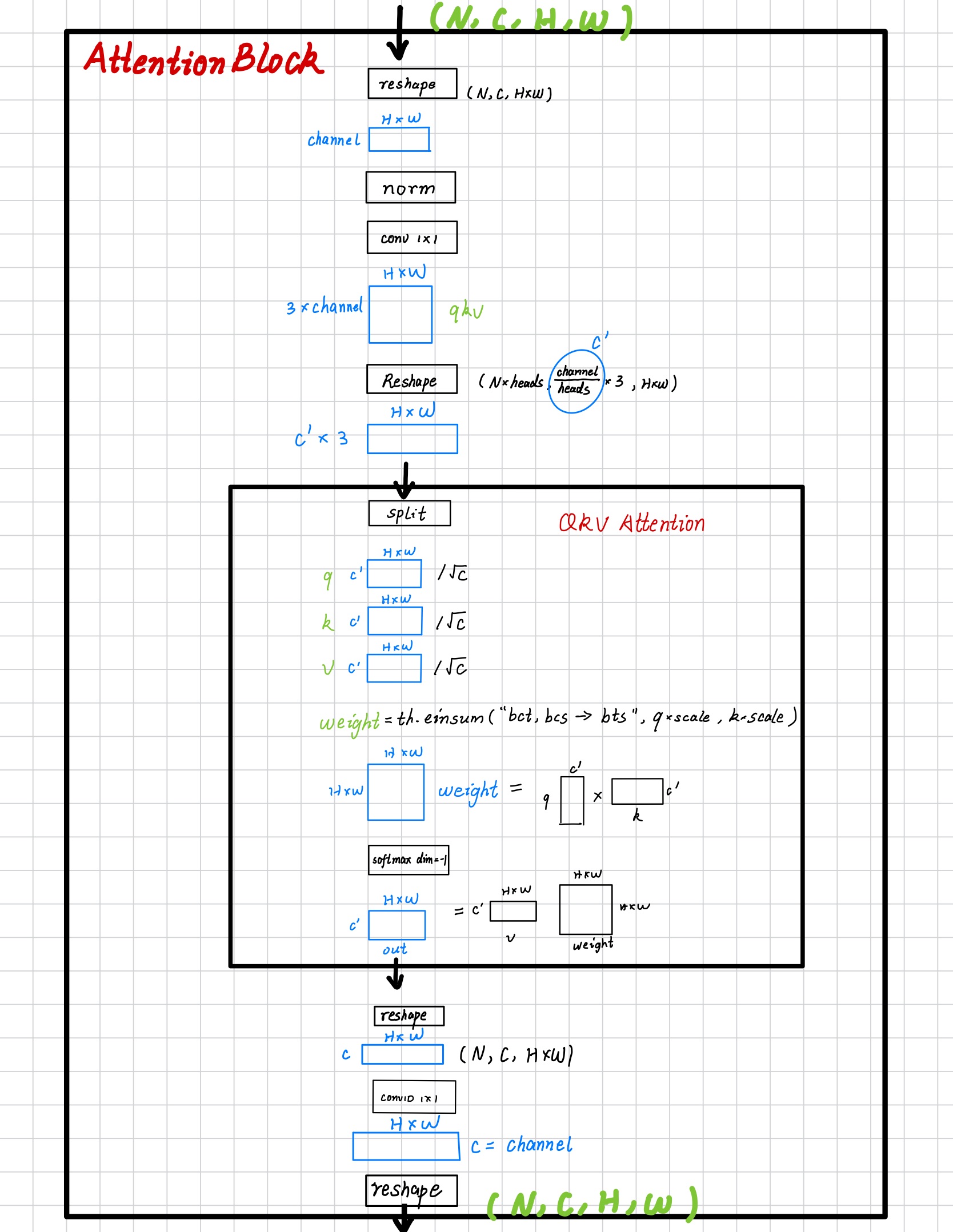
Attention Block
Unet