Insert Anything
Abstract
presents Insert Anything
trained once on our new AnyInsertion dataset
employing two prompting strategies to harmonize the inserted elements with the target scene while faithfully preserving their distinctive features
Extensive experiments on AnyInsertion, DreamBooth, and VTON-HD benchmarks demonstrate that our method consistently outperforms existing alternatives
Introduction
challenges remain
- Task-Specific Focus.
- Fixed Control Mode. (mask-guided editing, text-guided editing)
- Inconsistent Visual-Reference Harmony.
we introduce AnyInsertion dataset
- supports a wide range of insertion tasks
- contains 159k prompt-image pairs, 58k mask-prompt pairs, 101k text-prompt pairs
introduce Insert Anything, a unified framework of inserting (mask, text)
- leverage the multi-modal attention of DiT
- introduce in-context editing (already published by IC-LoRA,ACE++?)
- two prompting strategies
- mask-prompt diptych: left ref, right masked image
- text-prompt triptych: left ref, middle source, right generated
Related Work
Image Insertion
Our approach differs from these methods by leveraging in-context learning for efficient high-frequency detail extraction, eliminating the need for additional networks like ControlNet, and supporting both mask and text prompts.
- Person insertion:
Putting people in their place [cvpr2023]introduces a inpainting based method.ESP [eccv 2024]generates personalized figures guided by 2D pose and scene context.Text2Place [eccv 2024]leverages SDS loss to optimize semantic masks for accurate human placement. - Garment insertion:
OOTDiffusionemploys a ReferenceNet structure similar to a denoising UNet for processing garment images.CatVTONspatially concatenates garment and person images. - General object editing:
MimicBrushandAnyDoorboth support mask-guided insertion. AnyDoor utilizes DINOv2 for feature extraction andControlNet [iccv 2023]to preserve high-frequency details. MimicBrush uses a UNet [33] to extract reference features while maintaining scene context via depth maps and unmasked background latents.
Reference-Based Image Generation
Such as face features InstantID, stylistic attributes
Styledrop. These methods fall into two main categories:
those requiring test-time fine-tuning
Textual Invertsion, Dreambooth and those that adopt a
training-based approach IP-Adapter.
Though In-context LoRA which leverages DiT's in-context
learning capabilities, and Diptych Prompt, which enables
training-free zero-shot reference based generation through Flux
ControlNet inpainting model. Poor performance.
Unified Image Generation and Editing.
ACE [10], which employs a conditioning unit for multiple inputs; Qwen2vl-flux [23] uses a vision language model for unified prompt encoding; OminiControl [40] concatenates condition tokens with image tokens.
AnyEdit [49], Unireal [4], and Ace++ [25] provide partial support for image insertion tasks, but none offers a comprehensive solution for all three insertion types with both mask and text prompt support, which distinguishes our Insert Anything framework.
AnyInsertion Dataset
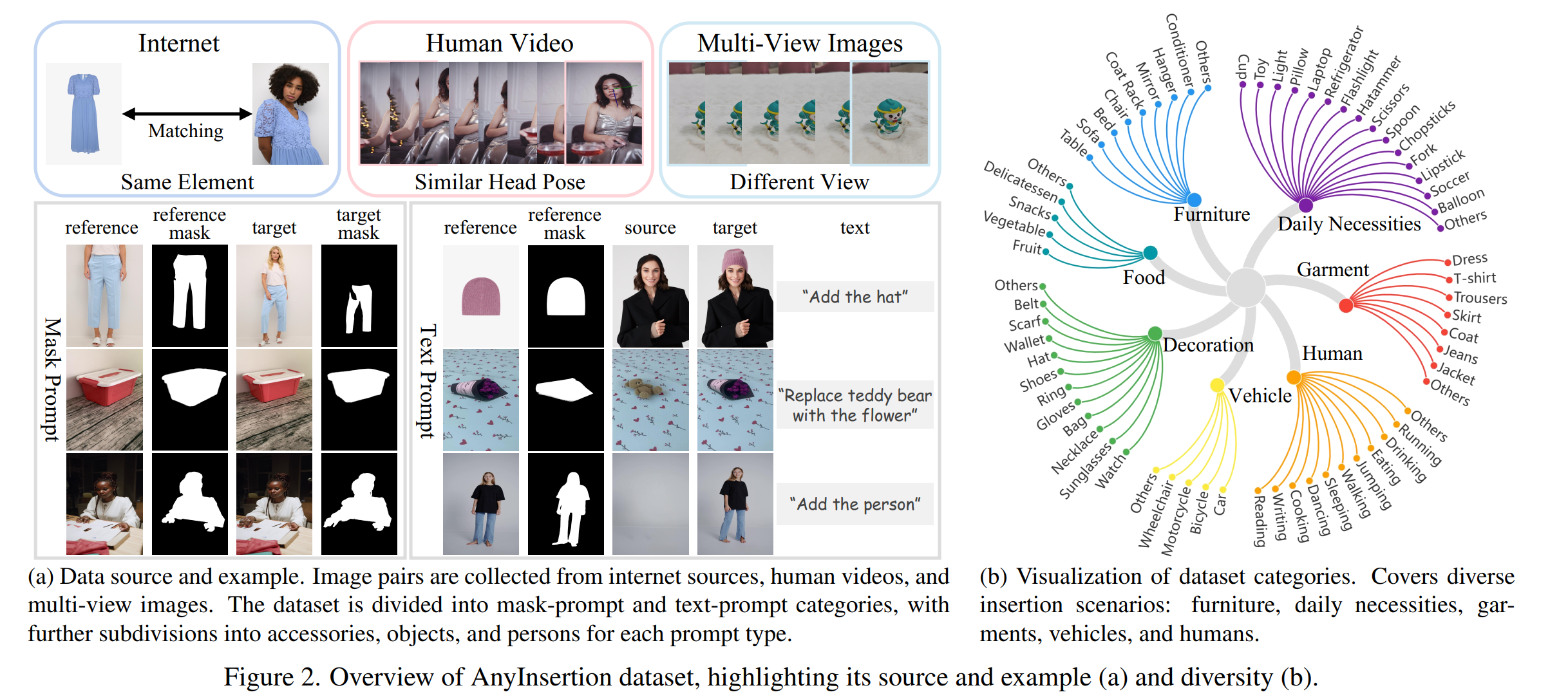
Comparison with Existing Datasets
Existing datasets suffer from several limitations:
- Limited Data Categories. FreeEdit [11]
FreeBenchdataset primarily focuses on animals and plants. VITON-HD [5] dataset specializes in garments. Even AnyDoor [3] and MimicBrush [2] include a large scale of data, they contain only very few samples related to person insertion.
- Restricted Prompt Types. FreeEdit [11] provides
only text-prompt data, while VITON-HD supports only mask-prompt
data.
- Insufficient Image Quality. AnyDoor and MimicBrush utilize a large volume of video data. These video datasets often suffer from low resolution and motion blur.
\[ \begin{array}{lcccc} \hline \text { Dataset } & \text { Theme } & \text { Resolution } & \text { Prompt } & \text { #Edits } \\ \hline \text { FreeBench [11] } & \text { Daily Object } & 256 \times 256 & \text { Text } & 131,160 \\ \text { VITON-HD [5] } & \text { Garment } & 1024 \times 768 & \text { Mask } & 11,647 \\ \text { AnyInsertion } & \text { Multifield } & \text { Mainly 1-2K} & \text {Mask/Text}& 159,908 \\ \hline \end{array} \]
Table 1. Comparison of existing image insertion datasets with our AnyInsertion dataset. AnyInsertion addresses the limitations of existing datasets by covering diverse object categories, supporting both mask- and text-prompt, and providing higher-resolution images suitable for various practical insertion tasks.
Data Construction
Data Collection
We employ image matching techniques
Lightglue [iccv 2023] to create paired target and reference
images and gather corresponding labels from internet sources.
object-related data: we select images from
Mvimgnet [cvpr 2023]which provides varying viewpoints of common objects, to serve as reference-target pairs.person insertion: we apply head pose estimation
On the representation and methodology for wide and short range head pose estimationto select frames with similar head poses but varied body poses from the HumanVid datasetHumanvid [Neurips 2024]which offers high-resolution video frames in real-world scenes. Frames with excessive motion blur are filtered out using blur detection [30], resulting in high-quality person insertion data.Data Generation: support two control modes:
- mask-prompt (diptych):
(reference image, reference mask, target image, target mask)useGrounded DINO [eccv 2024]andSegment Anything [iccv 2023]to generate reference and target masks. - text-prompt (triptych):
(reference image, reference mask, target image, source image, text)- source image: generate by a reversed inpainting of target image. use
flux fill devfor edit anddesign editfor removal.
- source image: generate by a reversed inpainting of target image. use
- mask-prompt (diptych):
Dataset Overview
- Training set: includes 159,908 samples across two
prompt types: 58,188 mask-prompt image pairs, 101,720 text-prompt image
pairs
- Test set: 120 mask-prompt pairs and 38 text-prompt pairs
Insert Anything Model
overview three key:
- reference image
- source image providing the background
- control prompt (either mask or text)
Goal:
- target image
Integrates three components
- a polyptych in-context format
- semantic guidance either text or reference image
- DiT based architecture in-context and multimodal attention
In-Context Editing
background removal: isolate the reference element. Following the approach \([3,37]\), we utilize the background removal process \(R_{\text {seg }}\) using Grounding-DINO and SAM to remove the background of the reference image, leaving only the object to be inserted.
Mask-Prompt Diptych. 2 Panel. Concatenates background removed ref image and partially masked source image. \(I_{\text {diptych }}=\left[R_{\text {seg }}\left(I_{\text {ref }}\right) ; I_{\text {masked_src }}\right]\) . The mask is like the IC-LoRA. \(M_{\text {diptych }}=\left[\mathbf{0}_{h \times w} ; M\right]\)
Text-Prompt Triptych. 3 Panel. \(I_{\text {triptych }}=\left[R_{\text {seg }}\left(I_{\text {ref }}\right) ; I_{\text {src }} ; \emptyset\right]\) . \(I_{\text {triptych }}=\left[R_{\text {seg }}\left(I_{\text {ref }}\right) ; I_{\text {src }} ; \emptyset\right]\) .
Multiple Control Modes
utilizing two dedicated branches: an image branch and a text branch. (same as flux fill dev?)
- Mask Prompt: image branch handles visual inputs, including the reference image, source image, and corresponding masks, concatenated with noise along the channel dimension to prepare for generation.
- Text Prompt: We design a specialized prompt
template:
A triptych with three side-by-side images. On the left is a photo of [label]; on the right, the scene is exactly the same as in the middle but [instruction] on the left.
Experiments
Experimental Setup
Implementation details:
Model: Flux fill dev
RANK: 256
BatchSize: mask prompt 8, text prompt 6.
Resolution: All images 768x768
Optimizer: Prodigy
Weight decay: 0.01
GPU: 4xA800 80g
Train Steps: 5000
Inference steps: 50
Test Datasets:
- Insert Anything: 40 object insertion, 30 garment insertion, 30 person insertion
- DreamBooth: 30 groups, one reference one target
- VTON-HD: standard benchmark for virtual try-on applications and garment insertion tasks.
Metrics: PSNR, SSIM, LPIPS, FID
Base lines:
- object and person insertion:
AnyDoor [cvpr 2024],Mimc Brush [arxiv 2024],ACE++ [arxiv 2025] - text prompt object insertion:
AnyEdit [arxiv 2024] - garment insertion:
ACE++ [arxiv 2025],OOTD Diffusion [arxiv 2024]andCATVTON [arxiv 2024].
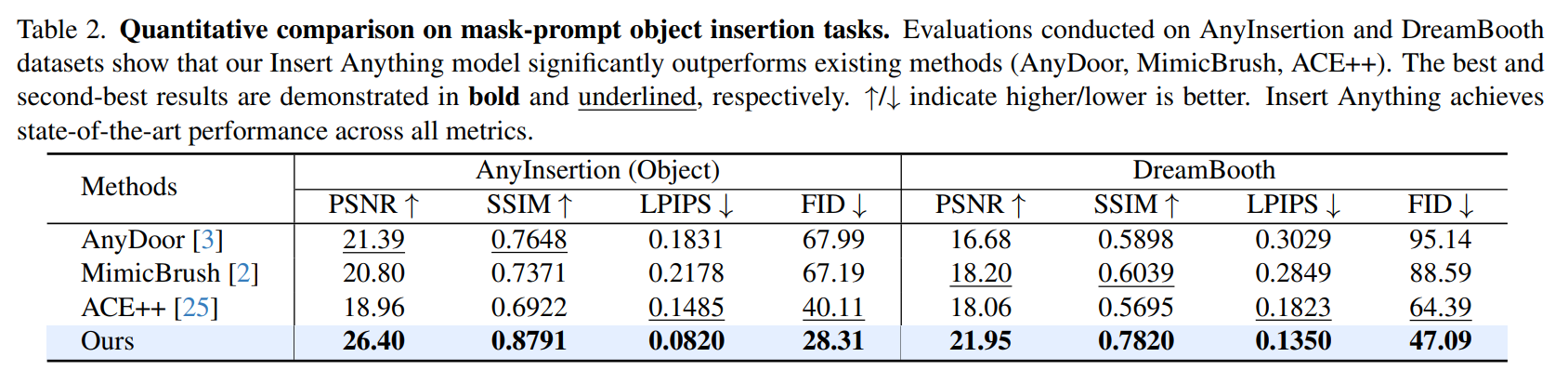
Quantitative Results
Object Insertion Results. As shown in Tables 2 and 3, Insert Anything consistently outperforms existing methods across all metrics for both mask-prompt and text prompt object insertion. For mask-prompt insertion, our approach substantially improves SSIM from 0.7648 to 0.8791 on AnyInsertion and from 0.6039 to 0.7820 on DreamBooth. For text-prompt insertion, we achieve a reduction in LPIPS from 0.3473 to 0.2011 , indicating significantly better perceptual quality. These improvements demonstrate our model's superior ability to preserve object identity while maintaining integration with the target context.
<img src="https://minio.yixingfu.net/blog/2025-05-23/ac8131702f2d3a394f6ce4524c64cc822b9cef3cfdcc22c6b2a804736fef4ead.png" width="50%">Garment Insertion Results.
Garment Insertion Results. Table 4 shows Insert Anything's consistent superiority over both unified frameworks and specialized garment insertion methods across all metrics on both evaluation datasets. On the widely used VTONHD benchmark, we improve upon the previous best results from specialized methods, reducing LPIPS from 0.0513 to 0.0484 , while simultaneously achieving substantial improvements in PSNR (26.10 vs. 25.64) and SSIM (0.9161 vs. 0.8903). The performance gap widens further when compared to unified frameworks like ACE++, highlighting our approach's effectiveness in combining task-specific quality with a unified architecture.

Person Insertion.
Person Insertion. Table 5 shows that Insert Anything significantly outperforms existing methods across all metrics for person insertion on AnyInsertion dataset. Our approach achieves notable improvements in structural similarity (SSIM: 0.8457 vs. 0.7654 ) and perceptual quality (FID: 52.77 vs. 66.84) compared to the previous best results. These improvements are particularly significant considering the challenge of preserving human identity during the insertion process.
<img src="https://minio.yixingfu.net/blog/2025-05-23/8a2c142ee79a0c7dcb9b844c10c75974b85cbde49fdbb98f96edd9c2f34dd43b.png" width="50%">Qualitative Results
