FaithDiff
FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolution
Introduction
Definition of SR: Image super-resolution (SR) aims to recover high-quality (HQ) images from low-quality (LQ) ones with unknown degradations.
Problem: challenging to restore faithful SR images with high reality and fidelity
Most state-of-the-art image SR methods rely on deep generative models
- GAN:
- Code Book:
- Latent Diffusion Models (LDMs):
- Enhance the encoder to extract degradation-robust
features:
Diff-bir [arxiv 2023],Xpsr [eccv 224],Pixel-aware stable diffusion [eccv 2024],Scaling up to excellence [cvpr 2024]. relying solely on improing the extracted features for guiding the diffusion process has limitations in achieving faithful restoration. - Different from the above methods, we unleash and finetune the diffusion model to identify usefull information from degraded inputs and boost faithful image SR
- Enhance the encoder to extract degradation-robust
features:
Seperate optimizing encoder and diffusion model is not good.
Contributions
- We propose an effective method, named FaithDiff, which unleashes diffsusion priors to better harness the powerful representation ablility of LDM for image SR.
- We develop a simple yet effective alignment module to align the latent representation of LQ inputs, encoded by the encoder, with the noisy latent of the diffusion model.
- We jointly fine-tune the encoder and the difffusion model to benefit from their inter-play.
- We quantitatively and qualitatiely demonstrate that our FaithDiff performs faorably against state-of-the-art methods on both synthic and rea-world bechmarks.
Related Work
Image SR is a highly ill-posed problem
- early approaches
Blind super-resolution with iterative kernel correction [cvpr 2019],Unfolding the alternating optimization for blind super resolution [NeurIPS 2020],Learning a single convolutional super-resolution network for multiple degradations [cvpr 2018]focus on devoloping methods to estimate degradation kernels for restoration RealESRGAN [cvpr 2021],Designing a practical degradation model for deep blind image super-resolution.[cvpr 2021]consider more complex degradation scenarios and propose high-order degradation models to address real-world degradations- GAN based methods [Real-esrgan, BSRGAN]
Real-world blind super-resolution via feature matching with implicit high-resolution priors. In ACM MM, 2022,Efficient and degradation-adaptive network for real-world image super-resolution. [eccv 2022],Real-esrgan [cvpr 2021],BSRGAN. [cvpr 2021]often suffer from perceptually unpleasant artifactsDetails or artifacts [cvpr 2022],Desra [icml 2023]attempt to mitigate this issue by penalizing regions with such artifacts. Nonetheless, these methods still struglle to recover fine details in LQ images - Diffusion based methods
SD1.5,SDXL, serval recent methods leverage generative priors to solve image SR problemDiffbir [ecc 2024],Xpsr [eccv 2024],StableSR.[ijcv 2024],Seesr [cvpr 2024],Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization [eccv 2024],supir [cvpr 2024].- StableSR
- Diffbir explicitly divvide the restoration process into two stages: degradation remoal and detail regeneration. It first uses MSE based restoration models to achieve degradation remoavl and then employs generative priors for detail enhancement.
- Supir also adopt a similar two-stage restoration approach.
FaithDiff
We first employ the encoder of a pre-trained VAE to map LQ inputs into the latent space and extract the corresponding LQ features.
Develop an alignment module to effectively transfer useful information from the latent LQ features and ensure them align well with the diffusion process.
Incorporate text embeddings, extracted from image descriptions using a pre-trained text encoder, as auxiliary information.
Jointly fine-tune the VAE encoder and the diffusion model.
Finally, obtain the restored image from refined features by a pre-trained VAE decoder
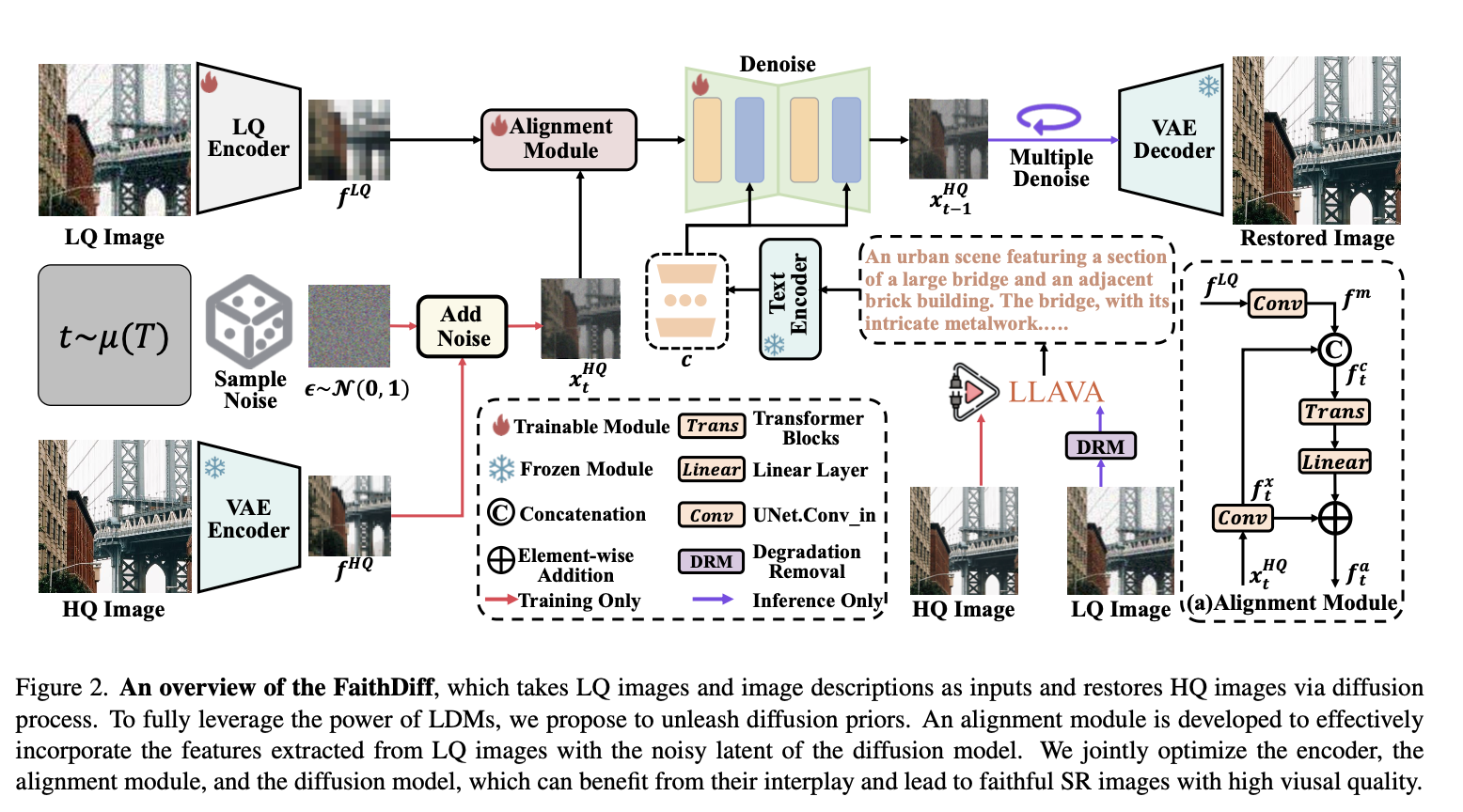
LQ feature extraction
DiffBir and Supir use the last channel of VAE (8 channels)
We extract features from the penultimate layer of the encoder \(f^{LQ}\)(512 channels)
Alignment module
We individually employ convolutional operations on the LQ features \(f^{LQ}\) and the noisy latent \(x_t^{HQ}\) and obtain their concatenation results as \(f_t^c\)
\(f_t^c\) is put into a stack Transformer blocks. We obtain the aligned features \(f_t^a\) as \[ \begin{aligned} & f_t^x=\operatorname{Conv}\left(x_t^{H Q}\right), f^m=\operatorname{Conv}\left(f^{L Q}\right), \\ & f_t^c=\operatorname{Concat}\left(f_t^x, f^m\right), \\ & \operatorname{Trans}\left(f_t^c\right)=\mathcal{T}_2\left(\mathcal{T}_1\left(f_t^c\right)\right), \\ & f_t^a=\operatorname{Linear}\left(\operatorname{Trans}\left(f_t^c\right)+f_t^x\right),\end{aligned} \]
we also leverage text embeddings as auxiliary information. These embedding are extracted from image descriptions by a pre-trained text-encoder
Experimental Results
Datasets and implementation details
Training dataset. We collect a training dataset of highresolution images from LSDIR [17], DIV2K [1], Flicker2K [20], DIV8K [7], and 10, 000 face images from FFHQ [12]. We generate LQ images following the same configuration as [43]. Similar to [44], we use the LLAVA [22] to generate textual descriptions for each image.
Synthetic test datasets. Similar to DASR [18], we employ different levels of degradations (D-level) to synthesize degraded validation sets of DIV2K [1] and LSDIR [17].
Real-world test datasets. To evaluate our approach in real scenarios, we first test on the dataset of RealPhoto60 [44]. We then collect a dataset, named RealDeg, of 238 images including old photographs, classic film stills, and social media images to evaluate our method across diverse degradation types. More details are included in the supplemental material.Real-world test datasets. To evaluate our approach in real scenarios, we first test on the dataset of RealPhoto60 [44]. We then collect a dataset, named RealDeg, of 238 images including old photographs, classic film stills, and social media images to evaluate our method across diverse degradation types. More details are included in the supplemental material.
Implementation details. We choose the base model of SDXL [26] as our diffusion model and use its VAE encoder as our LQ encoder. We train the proposed method using two A800 GPUs and adopt the AdamW optimizer [24] with default parameters. We crop images into patches of \(512 \times 512\) pixels during training and set the batch size as 256 . We first pre-train the proposed alignment module for 6,000 iterations with an initial learning rate of \(5 \times 10^{-5}\). We then fine-tune the whole network including the LQ encoder, the alignment module, and the diffusion model in an end-toend manner for 40,000 iterations. During the fine-tuning stage, the learning rate for the LQ encoder and other network components are initialized as \(5 \times 10^{-6}\) and \(10^{-5}\), respectively. The learning rates are updated using the Cosine Annealing scheme [23]. To further enhance the controllability of our proposed method, we employ an image descriptions dropout operation in training to enable classifier-free guidance (CFG) [8]. We empirically set the image descriptions dropout ratio to \(20 \%\) during training. For inference of FaithDiff, we adopt Euler scheduler [13] with 20 sampling steps and set CFG guidance scale as 5 .
Comparisons with the state of the art
- GAN based methods:
Real-ESRGAN,BSRGAN - Diffusion based methods:
StableSR,DiffBIR,PASD,DreamClear,SUPIR - Metrics:
PSNR,SSIM, and perceptual-oriented metricsLPIPS,MUSIQ,CLIPIQA+
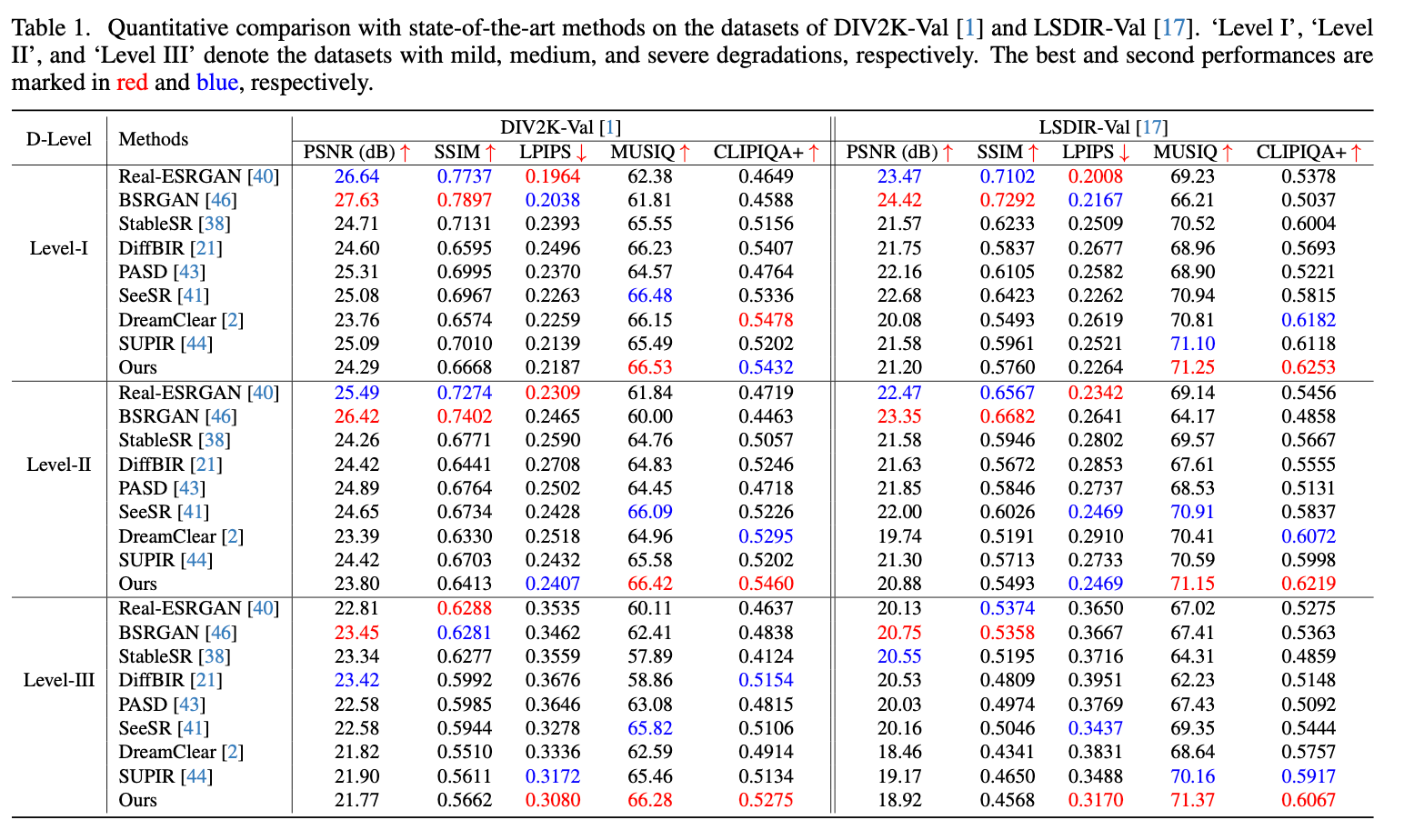
Evaluations on the synthetic datasets.
DIV2K, LSDIR
- Although
GAN based methodsperform best in terms ofPSNRandSSIMmetrics, they exihibit poor performance in terms ofMUSIQandCLIPIQA++metrics.
- visual comparisons on an LQ images with severe degradations from
LSDIR. The results genrated by GAN-based methodsReal-ESRGANexihibits perceptually unpleasant artifacts as shown in Figure 3(b). Existing diffusion based methods do not recovery satisfying results.StaleSRinjects LQ input into the diffusion process generates over-smoothed regions

Evaluations on the real-world datasets.
MUSIQ, CLIPIQA+
- As high resolution images are not available (512x512 resolution), we use non-reference metrics to evaluate the quality of restored images in Table 2.

- Figure 4 shows one example from
RealPhoto60 [44]and two examples from theRealDegdataset. The proposed method generates more realistic images with better fine-scale structures and details (Figure 4(h)).

Real-world OCR recognition
Evalutation Datasets:
ICDAR 2024 Occluded RoadText dataset and generate LQ images
with severe degradations using the same method employ different levels
of degradations similar to DASR.
- Recognition:
PaddleOCR v3

Analysis and Discussion
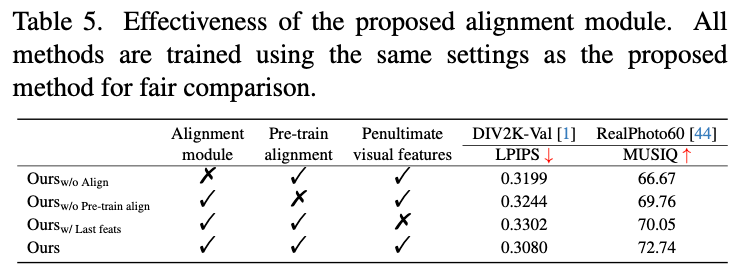
Effectiveness of the alignment module
- w/o align: apply one convolutional layer on the noisy latent as well as the LQ features and then add their results together.
- w/o pre-train align: does not pre-train the alignment module but directly trains it together with the whole network
- w last layer: use the visual features from the penultimate layer of the LQ-encoder instead of those from the last layer.
Effectiveness of unified feature optimization
Visualization of DAAMs
Conclusion
- we propose an effective image SR method, named FaithDiff
- We show that unleashing diffusion priors is more effective in exploring useful information from degraded inputs and restoring faithful results.
- We develop an alignment module that effectively incorporates the features extracted by encoder with the noisy latent of the diffusion model.
- Taking all components into one trainable network, jointly optimize the encoder, alignment module and the diffusion model.